本文示例使用的VMWare虚拟机,Linux系统版本是CentOS 7_64位,Hadoop的版本是Hadoop 2.8.2,JDK版本是1.8,使用的账号是创建的hadoop账号(参考Hadoop(二)Hadoop单机模式安装与运行)。
安装Hadoop之前要保证系统已经安装了Java JDK,并配置好了Java环境变量。
在前面文章中讲的Hadoop的单机模式,并没有启动HDFS和YARN的进程,通过jps命令发现只是启动了一个叫RunJar的进程。Hadoop通常是一个大的集群,具体来说是HDFS集群和YARN集群,如果这两个集群都只有一台机器,即是本文所讲的伪分布式。如果这两个集群都是有多台机器,那就是完全分布式了,也即是实际应用中的情形。
那么Hadoop的伪分布式如何操作呢?
一.准备工作
准备工作和Hadoop的单机模式操作一样(可参考Hadoop(二)Hadoop的HelloWorld(单机模式下的安装和使用)),主要包括包括两步:
在Hadoop的运行环境配置文件中配置Java的安装目录
编辑${HADOOP_HOME}/etc/hadoop/hadoop-env.sh文件,将JAVA_HOME设置为Java安装根路径。cd $HADOOP_HOME/etc/hadoop vim hadoop-env.sh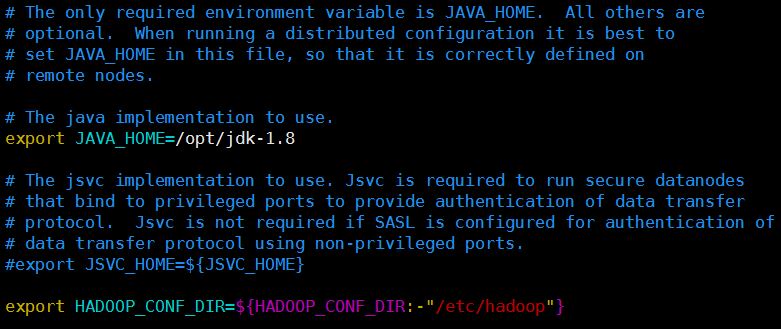
配置Hadoop的环境变量
在/etc/profile文件中增加:export HADOOP_HOME=/opt/hadoop-2.8.1 export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin比如我的
/etc/profile设置成如下图: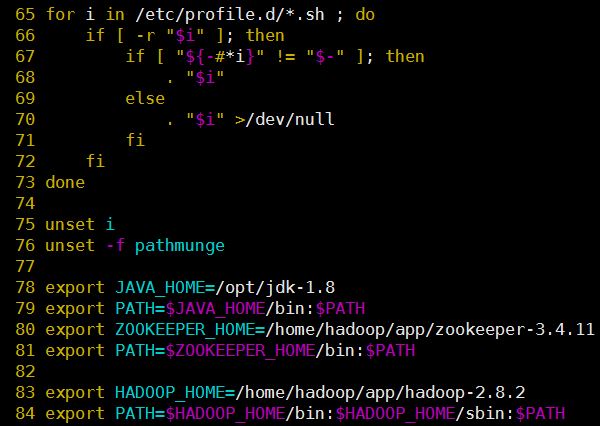
二.编辑配置文件
进入到 $HADOOP_HOME/etc/hadoop 目录下,开始Hadoop单节点集群配置。
关于Hadoop的主要配置文件的说明,可以参考官网文档:http://hadoop.apache.org/docs/current/ ,在左下角有Configuration的说明介绍。
1.编辑 core-site.xml
1 | <configuration> |
2.编辑 hdfs-site.xml
1 | <configuration> |
3.编辑 mapred-site.xml
目录下只有 mapred-site.xml.template 这个文件,使用 cp mapred-site.xml.template mapred-site.xml 命令复制一份配置文件,Hadoop会先去找mapred-site.xml这个配置文件。1
2
3
4
5
6
7<configuration>
<!-- MapReduce 程序运行的平台名称,使用yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.编辑 yarn-site.xml
1 | <configuration> |
三.格式化一个文件系统
执行命令:1
hdfs namenode -format
输出信息类似如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[hadoop@server04 hadoop]$ hdfs namenode -format
18/05/05 16:33:37 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hadoop
STARTUP_MSG: host = server04/192.168.128.4
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.8.2
……
……
18/05/05 16:33:39 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/05/05 16:33:39 INFO util.ExitUtil: Exiting with status 0
18/05/05 16:33:39 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server04/192.168.128.4
************************************************************/
四.开启Hadoop集群
1 | cd $HADOOP_HOME/sbin/ |
1.执行 start-dfs.sh 脚本
1 | ./start-dfs.sh |
中间会提示输入当前登录的hadoop账号的密码,最好是能配置免密登录就不用每次都输密码,具体怎么设置可参考Linux服务器的SSH连接使用一文。
最后输出信息如下:1
2
3
4
5
6
7
8
9
10
11
12
13[hadoop@server04 sbin]$ ./start-dfs.sh
Starting namenodes on [localhost]
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ECDSA key fingerprint is 44:92:44:48:ec:dc:71:9b:90:a0:6e:92:20:8b:cf:16.
Are you sure you want to continue connecting (yes/no)? yes
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
hadoop@localhost's password:
localhost: starting namenode, logging to /home/hadoop/app/hadoop-2.8.2/logs/hadoop-hadoop-namenode-server04.out
hadoop@localhost's password:
localhost: starting datanode, logging to /home/hadoop/app/hadoop-2.8.2/logs/hadoop-hadoop-datanode-server04.out
Starting secondary namenodes [localhost]
hadoop@localhost's password:
localhost: starting secondarynamenode, logging to /home/hadoop/app/hadoop-2.8.2/logs/hadoop-hadoop-secondarynamenode-server04.out
2.执行 start-yarn.sh 脚本
1 | ./start-yarn.sh |
输出信息如下:1
2
3
4
5[hadoop@server04 sbin]$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/app/hadoop-2.8.2/logs/yarn-hadoop-resourcemanager-server04.out
hadoop@localhost's password:
localhost: starting nodemanager, logging to /home/hadoop/app/hadoop-2.8.2/logs/yarn-hadoop-nodemanager-server04.out
五.在浏览器中查看Hadoop服务
1.查看HDFS文件系统
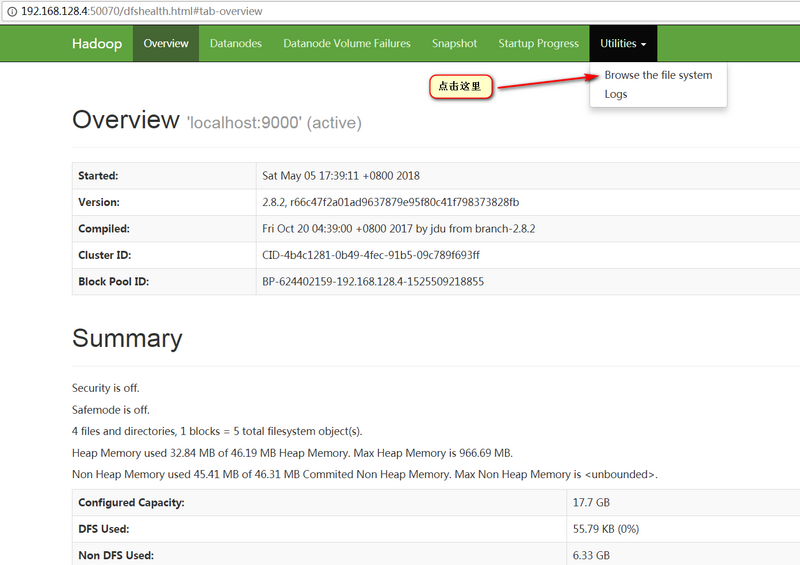
Hadoop NameNode 的默认端口是使用 50070, 可以再浏览器中访问 http://http://192.168.128.4:50070/ ,可以查看HDFS文件系统的使用情况,这里的192.168.128.4是我的虚拟机的ip地址。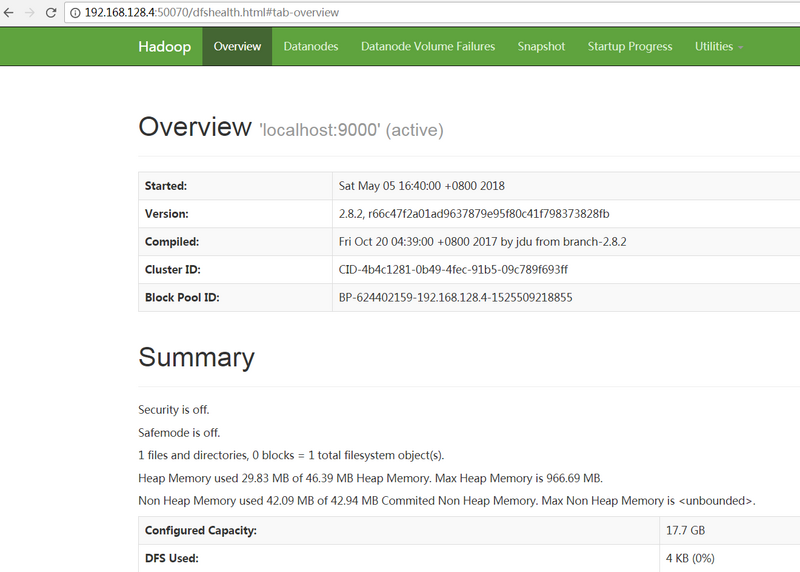
2.查看Hadoop集群和应用信息
在 8088 端口获取Hadoop集群和应用的信息:http://192.168.128.4:8088/ 。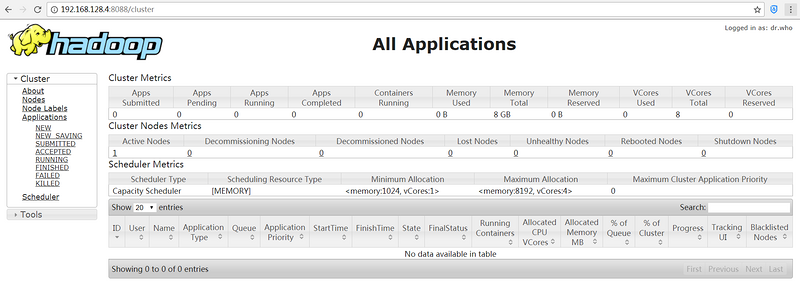
3.查看Secondary NameNode 的信息
在 50090 端口可以查看 secondary namenode 的信息:http://192.168.128.4:50090/ 。
4.查看DataNode 的信息
在 50075 端口可以查看 DataNode 的信息: http://192.168.128.4:50075/ 。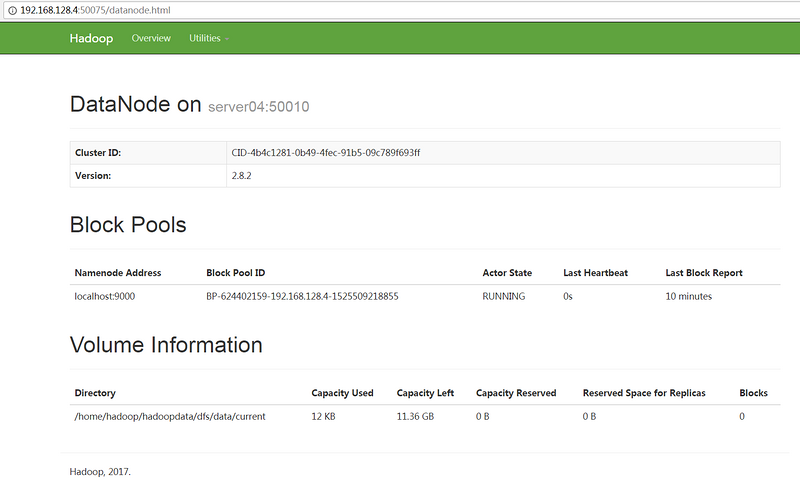
六.测试Hadoop单节点的HDFS文件系统
1.执行如下命令创建一个 HDFS 文件目录
1 | hadoop fs -mkdir /user |
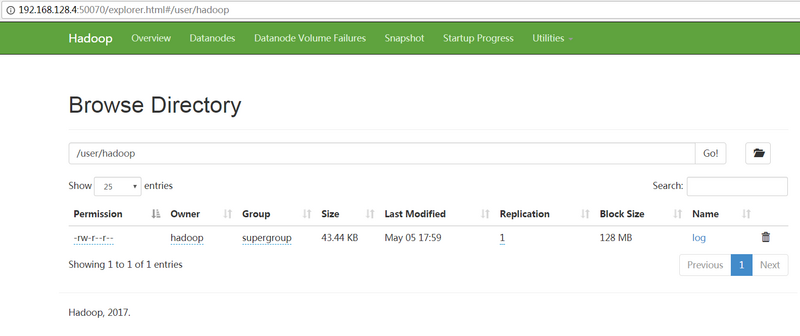
2.把本地文件(一个文件名为test.log,大小为44kb的文件)复制到Hadoop的分布式文件系统
1 | hadoop fs -put /home/hadoop/test.log /user/hadoop/log |
查看是否复制成功:1
2
3[hadoop@server04 ~]$ hadoop fs -ls /user/hadoop
Found 1 items
-rw-r--r-- 1 hadoop supergroup 44486 2018-05-05 17:59 /user/hadoop/log
在浏览器中也可以查看: