需求场景
比如有如下一个表T_NUM,里面有一列num是用逗号连接的字符串。
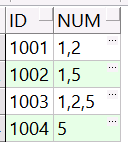
现在需要统计num列中每一个数字的出现的次数,例如1出现了三次,2出现了两次,5出现了三次,那么我们首先需要将num列通过“,”拆分后展示为多行。
解决方案
可以通过如下sql来实现拆分的功能,后文将对该sql进行详细解析。1
2
3
4
5
6
7
8
9
10SELECT
ID,
REGEXP_SUBSTR(NUM, '[^,]+', 1, LEVEL) AS NUM
FROM T_NUM
CONNECT BY REGEXP_SUBSTR(NUM, '[^,]+', 1, LEVEL) IS NOT NULL
-- 或者用 CONNECT BY LEVEL<=REGEXP_COUNT(NUM, ',') + 1 代替
AND ID=PRIOR ID
AND PRIOR SYS_GUID() IS NOT NULL
-- 或者用 AND PRIOR DBMS_RANDOM.VALUE() IS NOT NULL 代替
ORDER BY ID
查询结果:
解析
regexp_substr
上文中用到了Oracle中regexp_substr函数(该函数Oracle 10g+的版本才支持),这个函数可以通过匹配正则表达式来达到拆分字符串的目的。
函数格式如下:1
2
3
4REGEXP_SUBSTR(source_char, pattern)
REGEXP_SUBSTR(source_char, pattern, position)
REGEXP_SUBSTR(source_char, pattern, position, occurrence)
REGEXP_SUBSTR(source_char, pattern, position, occurrence, match_param)
- source_char: 必需的。目标字符串(需要处理的字符串)。它可以是 CHAR, VARCHAR2, NCHAR, NVARCHAR2, CLOB, 或 NCLOB 中的任何一种数据类型。
- pattern: 必需的。用于匹配的正则表达式,作为分割的标识
- position: 可选的。从目标字符串的第几个位置开始搜索,默认为1。注:在Oracle中字符串索引也是从1开始的,而不是0。
- occurrence:可选的。取出分割后的字符串数组的第几个子字符串,默认值为1。(分割后最初的字符串会按分割的顺序排列成组)
- match_param:可选的。匹配模式,”i”不区分大小写,”c”区分大小写。默认为”c”。
下面是几个regexp_substr函数使用的简单示例:
取分割后的第一个值:
1
2
3SELECT REGEXP_SUBSTR('123,,,ABC,!@#,,,', '[^,]+') FROM DUAL ;
-- 结果:123从第二个字符开始匹配,取分割后的第一个值:
1
2
3SELECT REGEXP_SUBSTR('123,,,ABC,!@#,,,', '[^,]+', 2) FROM DUAL ;
-- 结果:23取分割后的第二个值:
1
2
3SELECT REGEXP_SUBSTR('123,,,ABC,!@#,,,', '[^,]+', 1, 2) FROM DUAL ;
-- 结果:ABC从第一个字符开始,不区分大小写分割后的第一个值:
1
2
3SELECT REGEXP_SUBSTR('11a22A33a','[^A]+',1,1,'i') FROM DUAL;
-- 结果:11
-- 分析:正则表达式是以A为标识进行分割,而'i'标识不区分大小写,所以结果是11,而不是11a22从第一个字符开始,区分大小写分割后的第二个值:
1
2
3
4SELECT REGEXP_SUBSTR('11a22A33a','[^A]+',1,2,'c') FROM DUAL;
-- 结果: 33a
-- 分析: 正则表达式是以A为标识进行分割,而'c'标识区分大小写取分割后的所有结果:
1
2
3
4
5
6
7
8SELECT REGEXP_SUBSTR('123,,,ABC,!@#,,,', '[^,]+', 1, LEVEL)
FROM DUAL
CONNECT BY REGEXP_SUBSTR('123,,,ABC,!@#,,,', '[^,]+', 1, LEVEL) IS NOT NULL;
-- 结果:
-- 123
-- ABC
-- !@#
connect by 和 level
上面最后一个例子中用到了connect by 和 level,这里也简单说明一下。
level是什么?
level是在树形结构中、表示层级的伪列。从1开始递增,到层级的最深层次结束。
connect by 和树形结构
connect by 是Oralce中进行树状递归查询的关键字。
connect by 表示在构造树形结构时,上下级的确定方式或者用来查找下(上)级记录的条件,满足这个条件就拼到结果树里。
默认是从根开始,如connect by prior id=pid,表示构造树时,本记录的id是下条的pid,即找pid=本条id的记录做下条记录。
交换prior位置,表示从叶开始。如connect by id= prior pid,表示构造树时,本记录的pid是下条的id。
ps:prior表示构造树时,指定当前记录的字段作为源头。
多行数据的拆分
对于单独的字符串或单行数据可直接使用如下语法进行拆分:1
2
3
4SELECT
REGEXP_SUBSTR('1,2,4,5', '[^,]+', 1,LEVEL) AS NUM
FROM DUAL
CONNECT BY REGEXP_SUBSTR('1,2,4,5', '[^,]+', 1,LEVEL) IS NOT NULL;
但对于多行数据,使用上述语法就得到不到我们想要结果,例如在如下表中:
执行如下SQL1
2
3
4
5
6SELECT
ID,
REGEXP_SUBSTR(num, '[^,]+', 1,LEVEL) AS num1
FROM T_NUM
--WHERE ID IN (1,2)
CONNECT BY REGEXP_SUBSTR(num, '[^,]+', 1,LEVEL) IS NOT NULL;
得到的结果如下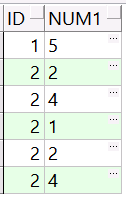
明显多了很多数据,为什么会出现这样的结果呢?
问题分析
是因为level本质是表示的层级数,并不是rownum这种单纯的序列。在connect by条件中若没有指定上下级关系,那么每一行都会作为其它行的父级与子级。
如果没有指定任何递归条件和查询条件,那么结果集应是如下的层级结构:
但是条件中限制了”CONNECT BY REGEXP_SUBSTR(num, ‘[^,]+’, 1,level) is not null”,也就是”5”是没有第二、第三层级的,所以应该把”5”的第一层级以外的层级及其子层级去掉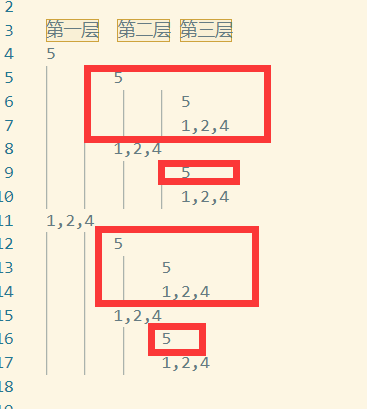
得到如下结果
再由于“REGEXP_SUBSTR(num, ‘[^,]+’, 1,level) as num1”,把对应层级的字符串分割出来,第一层取第一个数字,第二层取第二个数字…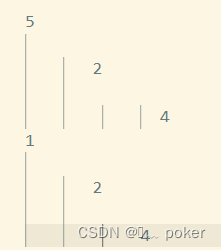
这样便得到了上面的 5-2-4-1-2-4的顺序。
问题处理
知道了多余的结果是重复递归造成的,所以要加上必要的递归条件过滤多余的结果。
既然原因是没有指定父子连接条件,那就指定一个条件,它限制自己只能是自己的父级或子级。1
2
3
4and prior id = id
-- prior的位置在此处不影响结果,它只是决定树的生长方向
-- and id = prior id
但是可以看出这是一个死循环的条件,父子关系相互指向,会导致 5->5->5->5…… 124->124->124… 永远结束不了。
加上如下条件,终止死循环(至于为什么能终止循环,原理尚不清楚,待补充)。1
2
3
4
5and PRIOR DBMS_RANDOM.VALUE() IS NOT NULL
-- 需要一个随机性足够大的随机数
-- 在某些场景或框架中,不允许直接调用DBMS_RANDOM.VALUE()
-- 可以使用SYS_GUID()替代

至此得到了期望的结果。
regexp_count
前面的解决方案中,可以使用 CONNECT BY LEVEL<=REGEXP_COUNT(NUM, ',') + 1 来替代 CONNECT BY REGEXP_SUBSTR(NUM, '[^,]+', 1, LEVEL) IS NOT NULL,LEVEL使用来控制层级的深度,这里用 regexp_count 函数也可以控制层级深度,该函数表示在给定字符串中匹配指定模式的次数。
regexp_count函数的格式:1
2
3REGEXP_COUNT(source_char, pattern)
REGEXP_COUNT(source_char, pattern, position)
REGEXP_COUNT(source_char, pattern, position, match_param)
里面的参数和 regexp_substr 是相同的意义与属性。
使用示例:
从第一个字符开始匹配。
1
2
3
4
5
6
7
SELECT
REGEXP_COUNT('ABCabacbcabc', '(a|b)c') "Result"
FROM dual;
-- 结果:3
-- 分析:在 ABCabacbcabc 中,有 3 个与 (a|b)c 匹配的内容,ac,bc 和 bc。从第7个字符开始匹配。
1
2
3
4
5
6SELECT
REGEXP_COUNT('ABCabacbcabc', '(a|b)c', 7) "Result"
FROM dual;
-- 结果:3
-- 分析:在 ABCabacbcabc 中,从第 7 个字符开始搜索,因此只有两个匹配的内容,bc 和 bc。不区分大小写匹配。
1
2
3
4
5
6SELECT
REGEXP_COUNT('ABCabacbcabc', '(a|b)c', 1, 'i') "Result"
FROM dual;
-- 结果:4
-- 分析:在 ABCabacbcabc 中,有 4 个匹配的内容,BC, ac,bc 和 bc。
PS:(1)如果前 3 个中的任意一个参数为 NULL, REGEXP_COUNT() 将返回 NULL。
正因为regexp_count函数可以返回一个给定的正则表达式模式在一个源字符串中出现的次数。所以CONNECT BY LEVEL<=REGEXP_COUNT(NUM, ',') + 1 可以替代 CONNECT BY REGEXP_SUBSTR(NUM, '[^,]+', 1, LEVEL) IS NOT NULL来控制查询的深度。