跳跃列表简称跳表,实质是有序链表加多级索引的数据结构。介绍跳表之前,先来看看跳表是怎么来的。
跳表的演化过程
假设有一个排好序的链表,如何更快地查找到其中的一个结点呢?如果是数组的话,可以用二分查找、差值查找等方法,但是对于链表这种结构,就只能从头开始遍历链表,这种做法效率比较低,时间复杂度是 O(n)。
那有没有什么办法来提高查询效率呢?我们可以为链表建立一个“索引”,这样查找起来就会更快,如下图所示,我们在原始链表的基础上,每两个结点提取一个结点建立索引,我们把抽取出来的结点叫做索引层或者索引,down属性表示指向原始链表结点的指针。
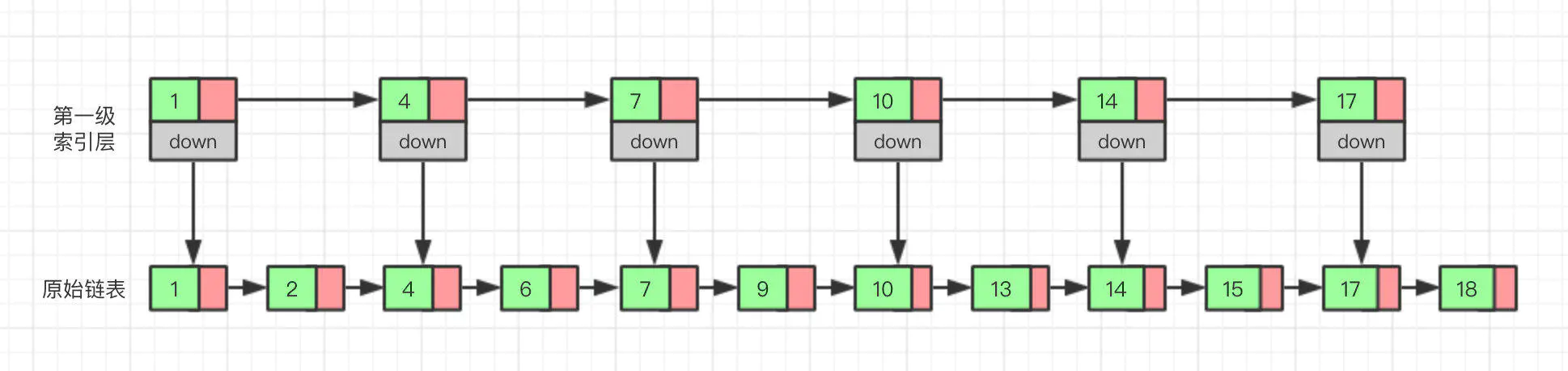
现在如果想查找一个数据,比如说 15,我们首先在索引层遍历,当遍历到索引层中值为 14 的结点时,会发现下一个结点的值为 17,所以我们要找的 15 肯定在这两个结点之间。这时我们就通过 14 结点的down指针,回到原始链表,然后继续遍历,这个时候只需要再遍历两个结点,就能找到我们想要的数据。至此,我们从头看一下,整个过程一共遍历了 7 个结点就找到了我们想要的值,如果没有建立索引层,而是直接查原始链表的话,我们需要遍历 10 个结点。
通过这个例子可以看出来,通过建立一个索引层,我们查找一个结点需要遍历的次数变少了,也就是查询的效率提高了。
那么如果我们给索引层再加一层索引呢?遍历的结点会不会更少呢,效率会不会更高呢?接下来我们再试一试就知道了。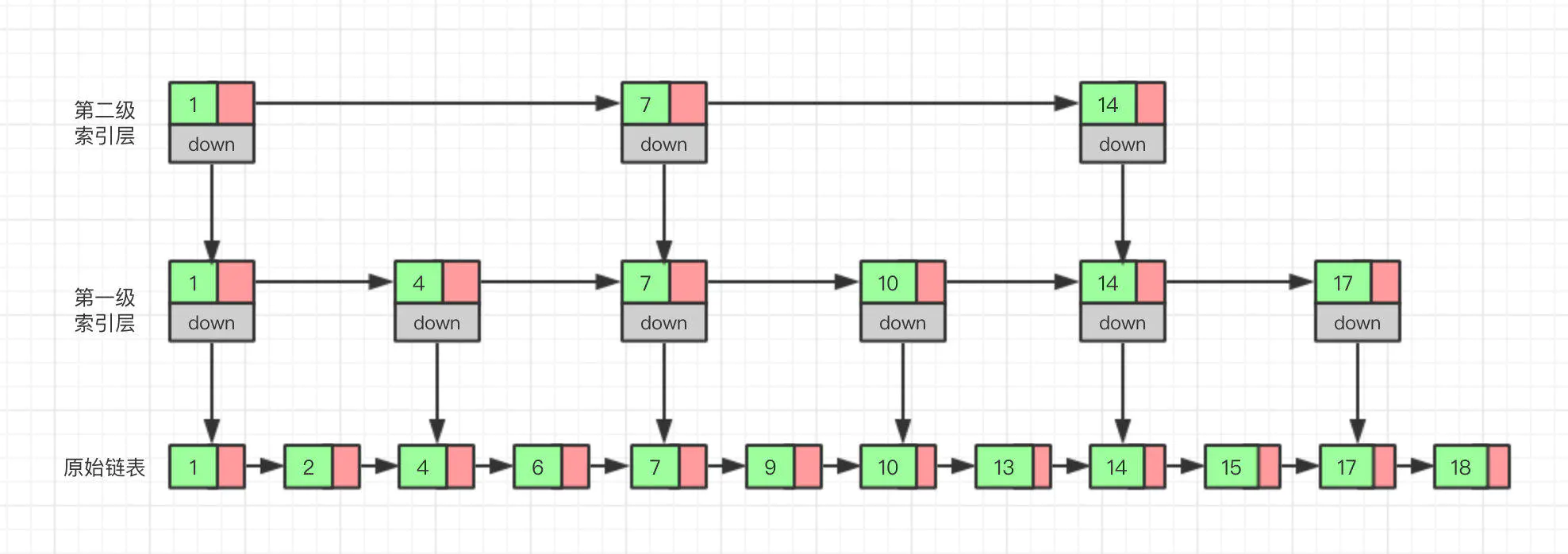
现在我们再来查找 15,从第二级索引开始,最后找到 15,一共遍历了 6 个结点,果然效率更高。
当然,因为我们举的这个例子数据量很小,所以效率提升的不是特别明显,如果数据量非常大的时候,我们多建立几层索引,效率的提升将会非常明显。
这种通过对有序链表加多级索引的结构,就是跳表了。
跳表查询的时间复杂度
按照上面提取索引的方法,我们可以不止提取两层索引,还可以提取更多的层次,保证每一层是下一层的结点数的一半,直到提取到某一层索引只剩下两个结点的情况是终止。对于这种结构的跳表时间复杂度是多少呢?
如果一个链表有$n$个结点,如果每两个结点抽取出一个结点建立索引的话,那么第一级索引的结点数大约就是$n/2$,第二级索引的结点数大约为$n/4$,以此类推第$m$级索引的节点数大约为$n/(2^m)$。
假如一共有$m$级索引,第$m$级的结点数为两个,通过上边我们找到的规律,那么得出$n/2^m=2$,从而求得$m=log(n)-1$。如果加上原始链表,那么整个跳表的高度就是$log(n)$。我们在查询跳表的时候,如果每一层都需要遍历$k$个结点,那么最终的时间复杂度就为$O(k*log(n))$。
那这个$k$值为多少呢,按照我们每两个结点提取一个基点建立索引的情况,我们每一级最多需要遍历两个结点,所以$k=2$。为什么每一层最多遍历两个结点呢?
因为我们是每两个结点提取一个结点建立索引,最高一级索引只有两个结点,然后下一层索引比上一层索引两个结点之间增加了一个结点,也就是上一层索引两结点的中值,看到这里感觉跳表的查询有点像二分查找了,每次我们只需要判断要找的值在不在当前结点和下一个结点之间即可。
查询的空间复杂度
跳表其实是用空间换时间的方式来提高查询效率,因为它需要额外存储多级索引,那么空间复杂度是多少呢?
还是根据上面分析的过程,如果一个链表有$n$个结点,如果每两个结点抽取出一个结点建立索引的话,那么第一级索引的结点数大约就是$n/2$,第二级索引的结点数大约为$n/4$,以此类推第$m$级索引的节点数大约为$n/2^m$,我们可以看出来这是一个等比数列。
这几级索引的结点总和就是$n/2+n/4+n/8…+8+4+2=n-2$,所以跳表的空间复杂度为$O(n)$。
那么我们有没有办法减少索引所占的内存空间呢?可以的,我们可以每三个结点抽取一个索引,或者没五个结点抽取一个索引。这样索引结点的数量减少了,所占的空间也就少了。
跳表的插入
跳表的插入首先是要查找到新数据要插入原始链表的哪个位置,这个过程其实就是查找的过程。找到插入点之后,使用随机化策略来决定新插入数据的索引列的提升高度x,然后就是插入高度为x的列,并维护跳跃表的结构。
这个随机化策略通常称为“抛硬币”的方式,也就是决定新节点是否会提升至上一层索引的几率是50%。为什么要用“抛硬币”的方式?
- 因为跳跃表删除和添加的节点是不可预测的,很难用一种有效的算法来保证跳表的索引部分始终均匀。
- 随机抛硬币的方法虽然不能保证索引绝对均匀分布,却可以让大体趋于均匀。
例如,现在我们要插入节点10,首先我们找到节点10在$L_1$层中的插入位置,如下图所示,我们知道节点10应该插入到节点9后面。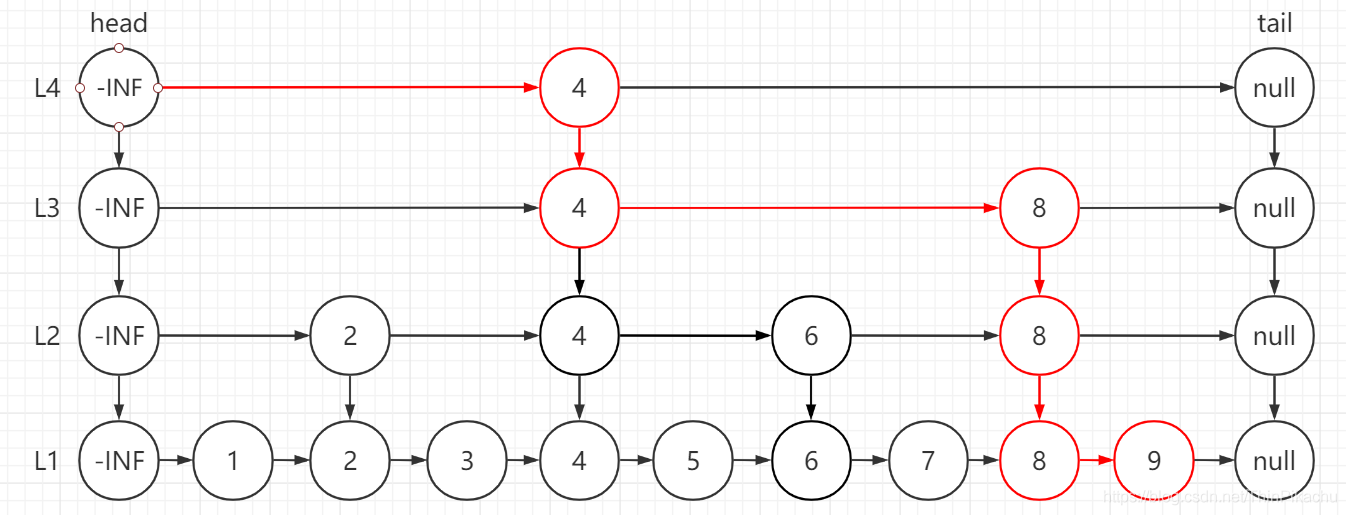
接着我们开始“抛硬币”,结果是”正面”,因此把节点10提升到上一层索引,多次为正则多次提升,当结果是“背面”或者到了一个新层时停止。在这个例子中假设5次都为“正面”,提升到了$L_5$层,提升之后需要重新维护跳跃表的结构。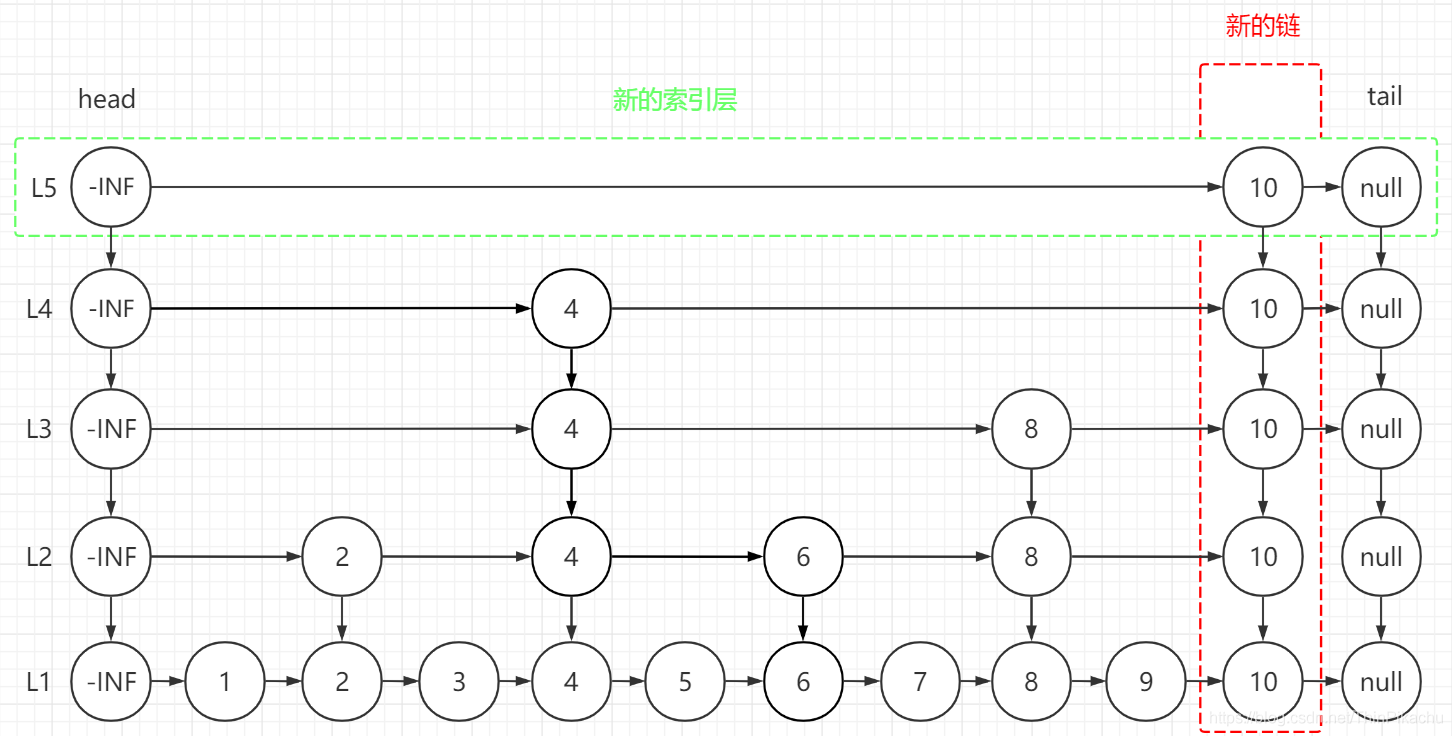
跳表的删除
跳表的删除就是从最上层开始自上而下查找数据,找到之后将该结点所在整列删除,并且将多余的空链删除(原链表除外),重新维护跳跃表。
例如,我们现在要删除结点10,首先找到了这个元素的位置。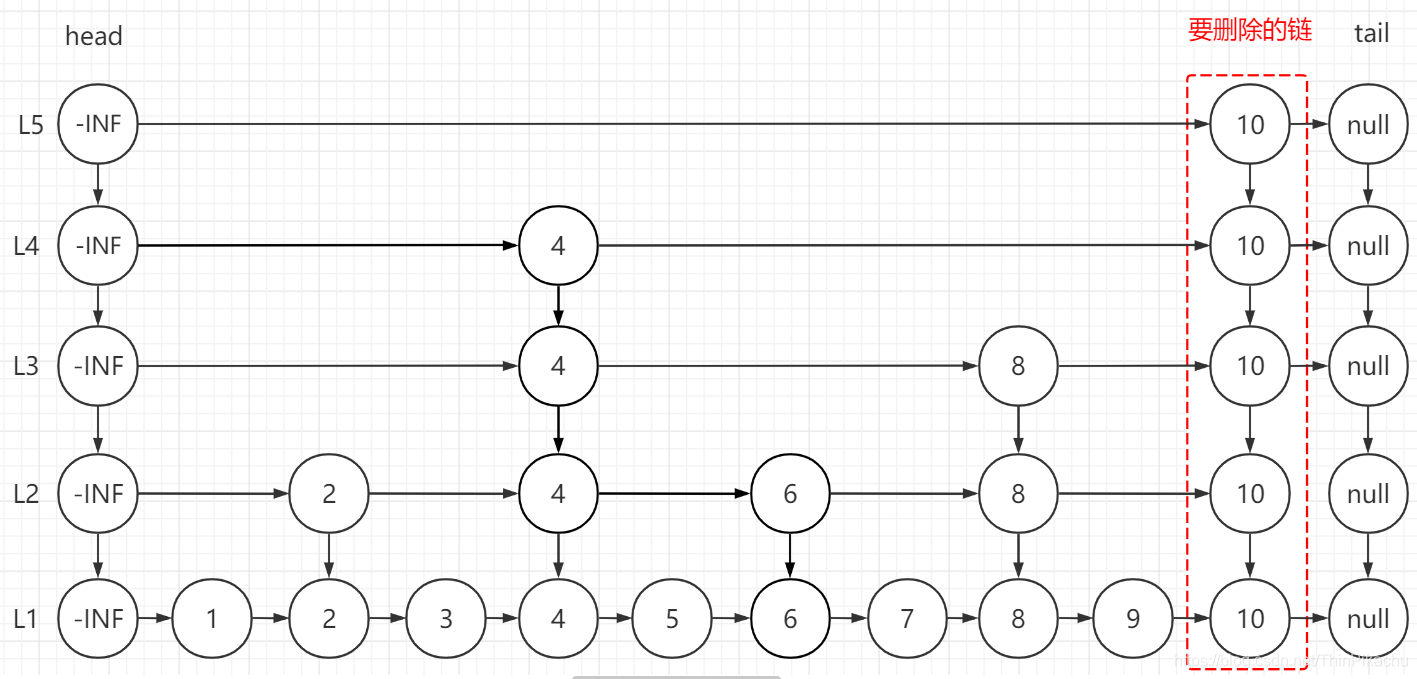
接着将结点10所在整列从表中删除,并且此时最高层$L_5$变成了空链。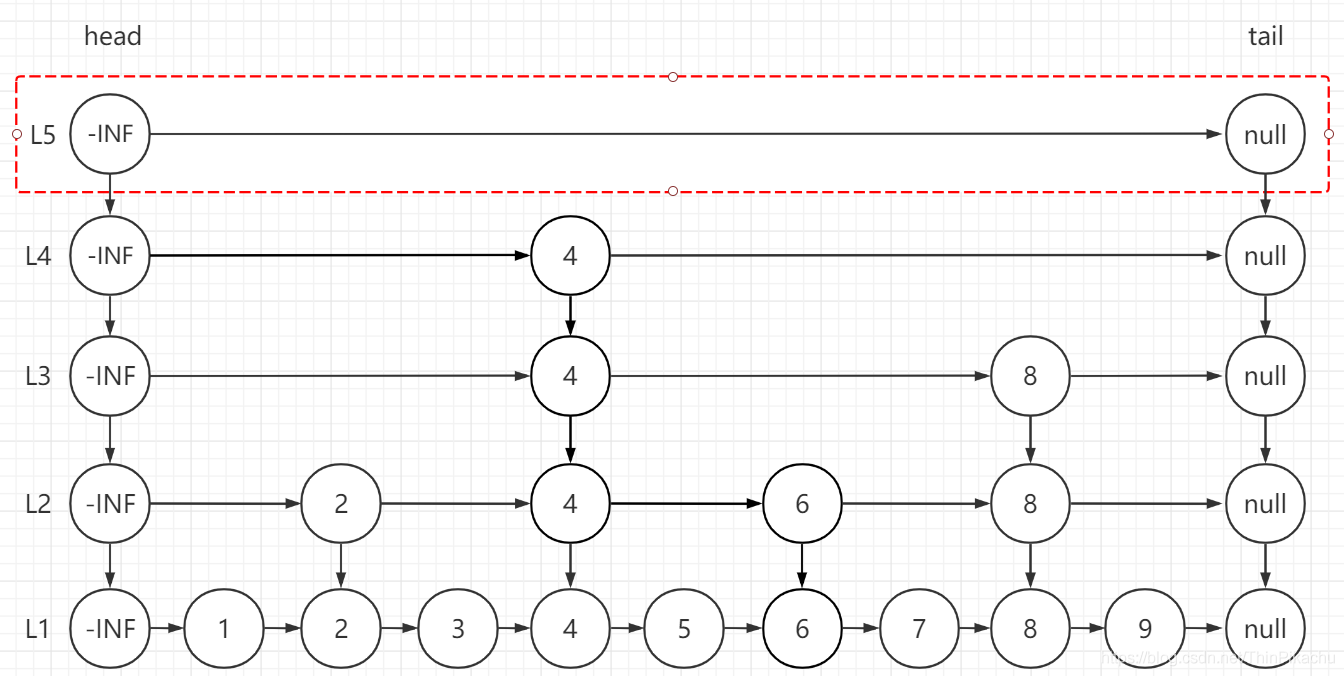
将空链删除并重新维护跳跃表。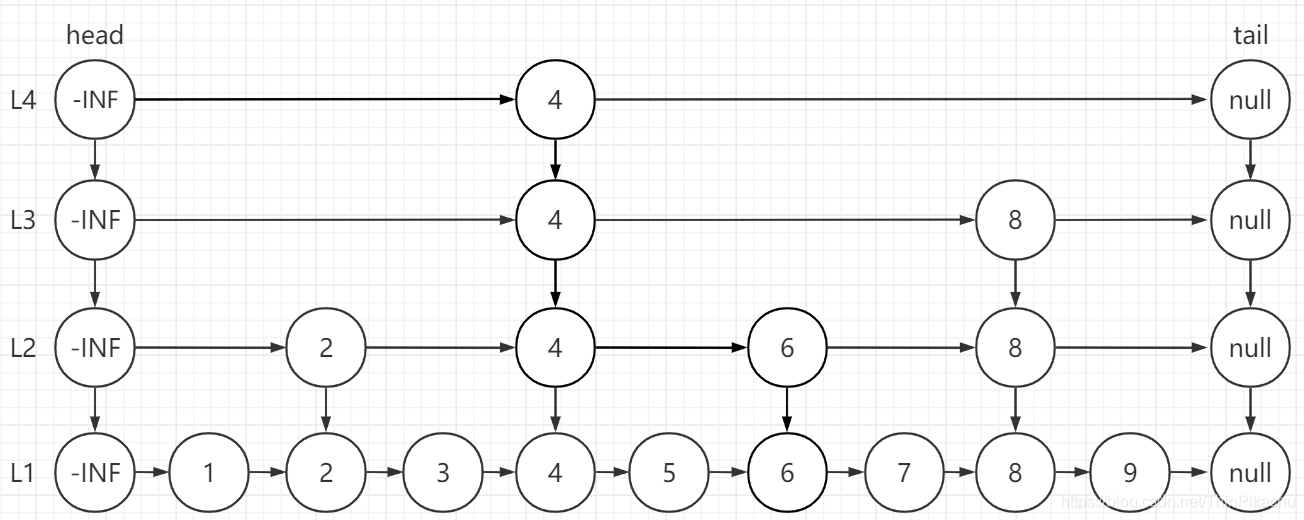
补充
跳跃表和二叉查找树的区别?
跳跃表的优点:维持结构平衡的成本比较低,完全依靠随机。
二叉查找树的优点: 在多次插入、删除后,需要rebalance来重新调整结构平衡。
链表中存在结点相等的情况处理
可以这样做:
- 可以让先插入的结点更靠近头结点。
- 删除结点的时候会把具有该值的所有结点删掉。
- 若待查找的值有多个的时候,查找返回的结果是具有最高索引层数的结点,若最高索引层数也相同,则返回更靠近头结点的结点。
跳表的Java实现
跳表代码实现
//略
Java API
Java API中提供了支持并发操作的跳跃表ConcurrentSkipListSet和ConcurrentSkipListMap。
有序的情况下:
- 在非多线程的情况下,应当尽量使用
TreeMap(红黑树实现)。 - 对于并发性相对较低的并行程序可以使用
Collections.synchronizedSortedMap将TreeMap进行包装,也可以提供较好的效率。但是对于高并发程序,应当使用ConcurrentSkipListMap。