bean的实例化模式
Spring容器实例化的bean有两种使用模式,一种是单例模式(singleton),另一种则是原型模式(prototype)。在默认的情况下,Spring中创建的bean都是单例模式的。
两种模式的区别
当一个bean的作用域设置为singleton, 那么Spring IOC容器中只会存在一个共享的bean实例,所有从容器中获取bean的请求,只要id与该bean定义相匹配,则只会返回这一个唯一实例。这个单一实例会被存储到单例缓存(singleton cache)中,并且所有针对该bean的后续请求和引用都将从缓存中读取。
如果是prototype作用域的bean,则每一次从容器中获取bean的请求(比如将其注入到另一个bean中,或者以程序的方式调用容器的getBean()方法)都会产生一个新的bean实例,相当与一个new的操作。
对于prototype作用域的bean,有一点非常重要,那就是Spring不能对一个prototype bean的整个生命周期负责,容器在初始化、配置、装饰或者是装配完一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。不管何种作用域,容器都会调用所有对象的初始化生命周期回调方法,而对prototype而言,任何配置好的析构生命周期回调方法都将不会被调用。清除prototype作用域的对象并释放任何prototype bean所持有的昂贵资源,都是客户端代码的职责。
那什么时候使用singleton模式,什么时候使用prototype模式呢?
一般情况下,有状态的bean需要使用prototype模式,而对于无状态的bean一般采用singleton模式(比如向Dao、Service这种)。什么是有状态呢?简单点说就是bean中带了一些数据,但这些数据是独立的、私有的,不能被共享的,当我某次从容器中拿到一个bean,对这个bean的数据有修改后,第二次去拿就不能拿这个修改后的bean,因为第二次的bean里面封装的数据跟第一次相比可能是需要不一样的。
怎么指定创建模式
第一种方法是在xml配置文件中配置bean时指定:1
2<bean class="com.lzumetal.order.OrderService" scope="singleton" init-method="init" destroy-method="destory">
</bean>
1 | <bean class="com.lzumetal.order.UserService" scope="prototype" init-method="init" destroy-method="destory"> |
第二种方式是以注解的方式指定:1
2
3
4("prototype")
public class MyTestOrderService {
}
Spring中创建的bean默认都是单例模式的,我们可以查看Scope注解的源码:1
2
3
4
5
6
7
public Scope {
String value() default ConfigurableBeanFactory.SCOPE_SINGLETON;
//省略...
}
prototype陷阱
当对某个类设定为 prototype,比如TestProcessor:1
2
3
4("prototype")
public class TestProcessor {
}
另外有一个TestController类中注入了一个TestProcessor实例:1
2
3
4
5
6
7
public class TestController {
private TestProcessor testProcessor;
}
当我们从在TestController中去使用 testProcessor 的时候,发现不同的线程拿到的 testProcessor 其实还是同一个。原因是TestController它是单例的,它只会实例化一次,并且实例化的时候注入一个TestProcessor实例。所以这种情况下需要放弃使用@Autowired方式,而是在需要的时候每次在从容器中去获取TestProcessor实例。
BeanDefinition
BeanDefinition是Spring实例化bean过程中一个非常重要的类,当Spring容器启动时,会扫描哪些类需要被实例化,然后根据这些类是xml配置的还是注解配置的,做相应的解析,将解析的数据封装在一个BeanDefinition对象中,包括bean的全类名、成员变量、作用域(Scope)、init方法、destroy方法、是否是懒加载等,这些BeanDefinition对象存放在一个map中。此后,Spring容器就可以使用一个BeanDefinition对象里的信息,利用反射技术生成一个对应的bean实例。
ObjectFactory
ObjectFactory是一个接口,它可关联某一类型的 Bean,仅提供一个getObject()方法用于返回目标 Bean 对象,ObjectFactory 对象被依赖注入或依赖查找时并未实时查找到关联类型的目标 Bean 对象,在调用 getObject() 方法才会依赖查找到目标 Bean 对象。
根据 ObjectFactory 的特性,可以说它提供的是延迟依赖查找。通过这一特性在 Spring 处理循环依赖(字段注入)的过程中就使用到了 ObjectFactory,在某个 Bean 还没有完全初始化好的时候,会先缓存一个 ObjectFactory 对象(调用其 getObject() 方法可返回当前正在初始化的 Bean 对象),如果初始化的过程中依赖的对象又依赖于当前 Bean,会先通过缓存的 ObjectFactory 对象获取到当前正在初始化的 Bean,这样一来就解决了循环依赖的问题。
Spring如何处理循环依赖
什么是循环依赖?
简单来讲,就是有一个 A 对象,创建 A 的时候发现 A 对象依赖 B,然后去创建 B 对象的时候,又发现 B 对象依赖 C,然后去创建 C 对象的时候,又发现 C 对象依赖 A。这就是所谓的循环依赖。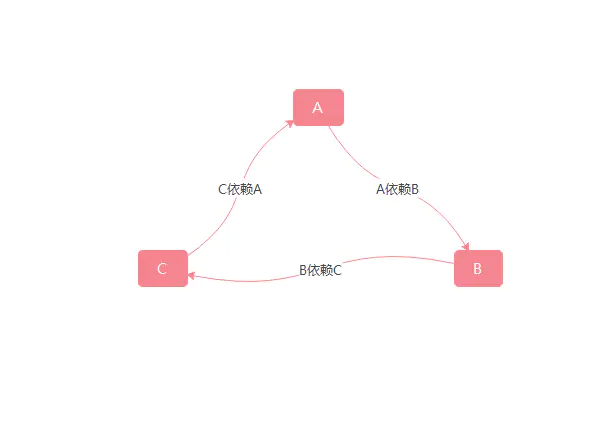
Spring可以解决循环依赖吗
有两种循环依赖的情况Spring是解决不了的,一是原型模式的bean的循环依赖,另一种是有参构造器的循环依赖。Spring可以解决单例模式下通过field属性注入方式实例化bean的循环依赖。
对于
@Autowired修饰的属性,类中并没有setter方法,Spring是如何注入属性的呢?答案是反射。
首先看原型模式bean循环依赖的情况1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
("prototype")
public class A {
private B b;
}
("prototype")
public class B {
public C c;
}
("prototype")
public class C {
public A a;
}
启动项目会抛出异常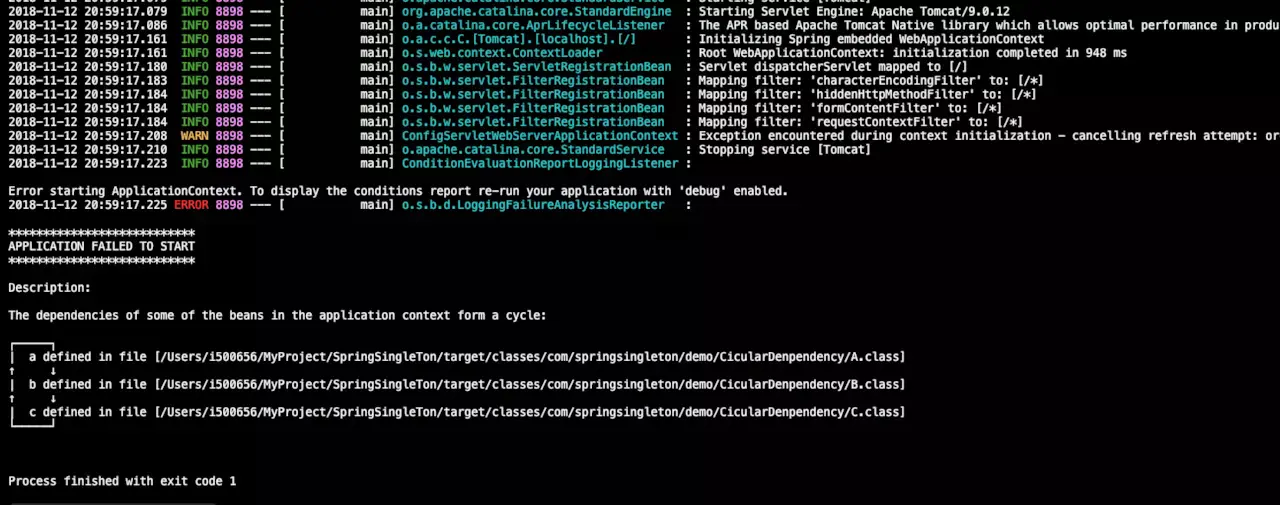
再看有参构造器循环依赖的情况1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class A {
public A(B b) { }
}
public class B {
public B(C c) {
}
}
public class C {
public C(A a) { }
}
启动项目也会抛出异常
field属性注入方式的循环依赖1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class A {
private B b;
}
public class B {
public C c;
}
public class C {
public A a;
}
项目启动成功
Spring是如何解决循环依赖的
Spring是通过三级缓存来解决循环依赖的。
什么是三级缓存
Spring中的这三级缓存指的是DefaultSingletonBeanRegistry类中的三个map。1
2
3
4
5
6
7
8/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
下表是三级缓存的说明:
| 名称 | 描述 |
|---|---|
| singletonObjects | 一级缓存,存放完整的 Bean。 |
| earlySingletonObjects | 二级缓存,存放提前暴露的Bean,Bean 是不完整的,未完成属性注入和执行 init 方法。 |
| singletonFactories | 三级缓存,存放的是ObjectFactory。 |
- 所有被 Spring 管理的 Bean,最终都会存放在 singletonObjects 中,这里面存放的 Bean 是经历了所有生命周期的(除了销毁的生命周期),完整的,可以给用户使用的。
- earlySingletonObjects 存放的是已经被实例化,但是还没有注入属性和执行
init方法的 Bean。这种提前暴露对象的方式是解决循环依赖的一个巧妙设计。 - singletonFactories 存放的是生产 Bean 的工厂实例(
ObjectFactory对象),ObjectFactory可以通过getObject()拿到它的泛型对应的那个Bean实例。
Bean 都已经实例化了,为什么还需要一个生产 Bean 的工厂呢?这里实际上是跟 AOP 有关,如果项目中不需要为 Bean 进行代理,那么这个 Bean 工厂就会直接返回一开始实例化的对象,如果需要使用 AOP 进行代理,那么这个工厂就会发挥重要的作用了,这也是为什么要用三级缓存而不用二级缓存的原因,后面会再详细说明。
过程分析
DefaultSingletonBeanRegistry有一个重要方法getSingleton,这个方法就是从单例缓存池中获取 Bean 的实例,下面是源码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName); //首先通过beanName从一级缓存获取bean
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { //如果一级缓存中没有,并且beanName映射的bean正在创建中
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName); //从二级缓存中获取
if (singletonObject == null && allowEarlyReference) { //二级缓存也没有,并且允许提前拿到引用
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); //从三级缓存获取
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject(); //获取到bean
this.earlySingletonObjects.put(beanName, singletonObject); //将获取的bean提升至二级缓存
this.singletonFactories.remove(beanName); //从三级缓存删除
}
}
}
}
return singletonObject;
}
以上代码很容易理解,分别尝试从一级,二级,三级缓存中获取BeanName对应的bean,如果三级缓存中有,则将三级缓存中的对象放到二级缓存中,清除三级缓存。另外,上面的代码中isSingletonCurrentlyInCreation(beanName)方法是beanName对应的实例是否正在创建中,创建中指的是 bean 对象已经创建了但是没有完成初始化。allowEarlyReference参数则是表示是否并且允许提前拿到bean对象的引用,默认是true。
至此,我们可以来分析Spring解决循环依赖的过程。在A依赖B且B依赖A的这种场景中,在A进行实例化完成以后,将A对应的ObectFactory放入三级缓存中,然后填充A的属性,这时候发现持有B的引用,进而创建B的bean(重复A的创建过程),B进行属性填充时会去从缓存中获取A的bean,此时的A是一个未初始化半成品存在于三级缓存中,当B属性填充完成以后,会从将B的bean对象放入一级缓存中,并从二三级缓存中删除B。继续填充A,A完成初始化后将A的bean对象也放入一级缓存中,并从二三级缓存中删除A对象。
为什么需要三级缓存
在上面的分析过程中似乎有二级缓存就够了,为什么需要三级呢?确实,在创建普通单例bean实例(没有代理)的时候,二三级缓存其实没区别。