什么是Elasticsearch?
Elasticsearch是一个开源的分布式、RESTful风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。
Lucene是一个高效的,基于Java的全文检索库。但由于它仅仅是一个库,集成到应用中时还需要调用Lucene的api写大量繁琐的Java代码。而Elasticsearch则是基于Lucene作了一层封装,提供出了一套简单一致的 RESTful API 来帮助我们实现存储和检索。
基本概念
全文搜索(Full-text Search)
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
在全文搜索的世界中,存在着几个庞大的帝国,也就是主流工具,主要有:
- Apache Lucene
- Elasticsearch
- Solr
- Ferret
倒排索引(Inverted Index)
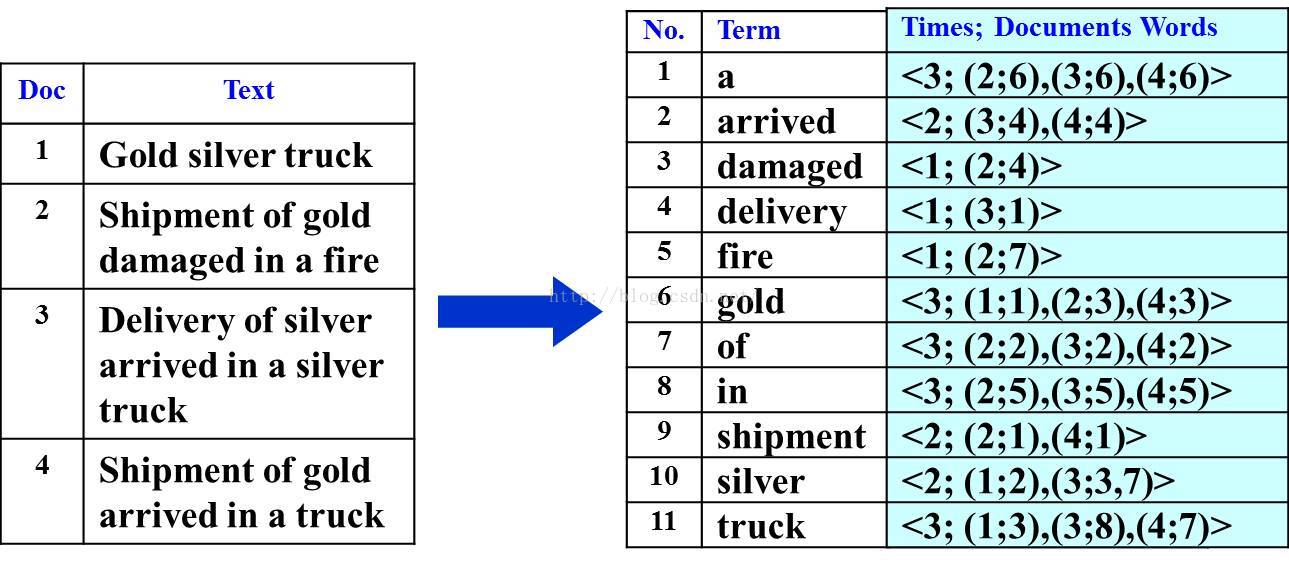
该索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。Elasticsearch能够实现快速、高效的搜索功能,正是基于倒排索引原理。
如下就是一个倒序索引的示意图,左边是Document记录,右边是分词后把根据单词构建了一个索引,对每个单词都记录了单词出现的次数,以及出现在哪个Document的哪个位置,这样根据这个单词索引表就能很快定位到检索出来的Document,并且还可以进行单词高亮显示。
节点 & 集群(Node & Cluster)
Elasticsearch 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个Elasticsearch实例。单个Elasticsearch实例称为一个节点(Node),一组节点构成一个集群(Cluster)。
索引(Index)
Elasticsearch 数据管理的顶层单位就叫做 Index(索引),相当于关系型数据库里的数据库的概念。注意:每个Index的名字必须是小写。
文档(Document)
Index里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示。例如:1
2
3
4
5{
"user": "张三",
"age": "31",
"department": "销售部"
}
同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
字段(Field)
每个Document都类似一个JSON结构,它包含了许多字段,每个字段都有其对应的值,多个字段组成了一个 Document,可以类比关系型数据库数据表中的字段。
在 Elasticsearch 中,文档(Document)归属于一种类型(Type),而这些类型存在于索引(Index)中,下图展示了Elasticsearch与传统关系型数据库的类比:
类型(Type)
Document 可以分组,比如employee这个 Index 里面,可以按部门分组,也可以按职级分组。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document,类似关系型数据库中的数据表。
举个例子,商品Index,里面存放了所有的商品数据,即商品Document。但是商品分很多种类,每个种类的Document的Field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊Field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊Field。
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
比如有两个Document数据如下:1
2
3
4
5
6
7
8{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
1 | { |
从上面的举例可以看出,其实Type和关系型数据库的表的概念是很不一样。在传统的关系型数据库中,各个”table”之间是互相独立的,在一个表中的列都与另一个表相同名称的列无关。而在Elasticsearch中,同一 Index 下,不同的Type是存储在同一个索引中的(lucene的索引文件)。
多Type的弊端:1)因为同一 Index 下,不同的Type的同一个字段,会被当作同一个Field,在处理这个Feild时会出现冲突的情况。比如,同一个Index中”deleted”字段在TypeA里是存储日期值,在TypeB里存储布尔值。2)同一 Index 下,如果TypeA有一个字段而TypeB中不需要这个字段,会造成稀疏存储的情况,浪费了存储资源。
所以:从Elasticsearch 6.x开始推荐只使用单Type,但仍兼容多Type;Elasticsearch 7.x中一个Index里只能有一个Type;而从Elasticsearch 8.x开始Type将被废弃。
分片(Shard)
如果一个Index的数据量非常大,单一节点无法存储这么多数据;或者单个节点处理搜索请求,响应太慢。Elasticsearch可以将一个索引中的数据切分为多个Shard,分布在多个节点上存储。每个Shard本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片的两个优点:
- 可以横向扩展,存储更多数据
- 让搜索和分析等操作分布到多个节点上去执行(即分布式、并行操作),提升吞吐量和性能。
副本(Replica)
如果一个节点出现故障或宕机,此时节点上分片的数据将无法访问,因此有必要为每个Shard创建多个Replica副本。Replica副本是一种容错保障机制,它有如下两个重要的作用:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,复制分片(Replica Shard)从不与主分片(Primary Shard)置于同一节点上。
- 扩展系统的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。