在JDK的bin目录下有很多命令行工具:
可以看到各个工具的大小基本上都稳定在17kb左右,这个不是JDK开发团队刻意为之的,而是因为这些工具大多数是jdk\lib\tools.jar类库的一层薄包装而已,他们的主要功能代码是在tools类库中实现的。
命令行工具的好处是:当应用程序部署到生产环境后,无论是直接接触物理服务器还是远程telnet到服务器上都会受到限制。而借助tools.jar类库里面的接口,我们可以直接在应用程序中实现功能强大的监控分析功能。
常用命令
这里主要介绍如下几个工具:
- jps:查看本机java进程信息
- jstack:打印线程的栈信息,制作 线程dump文件
- jmap:打印内存映射信息,制作 堆dump文件
- jstat:性能监控工具
- jhat:内存分析工具,用于解析堆dump文件并以适合人阅读的方式展示出来
- jconsole:简易的JVM可视化工具
- jvisualvm:功能更强大的JVM可视化工具
jps
显示当前所有java进程pid的命令,我们可以通过这个命令来查看到底启动了几个java进程(因为每一个java程序都会独占一个java虚拟机实例),不过jps有个缺点是只能显示当前用户的进程id,要显示其他用户的还只能用linux的ps命令。
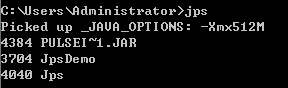
执行jps命令,会列出所有正在运行的java进程,其中jps命令也是一个java程序。前面的数字就是进程的id,这个id的作用非常大,后面会有相关介绍。
jps命令的语法格式:1
jps [options] [hostid]
如果不指定hostid就默认为当前主机或服务器。命令行参数选项说明如下:
- -m 输出传入main方法的参数
- -l 输出main类的全限定名或Jar的完整路径名
- -v 输出传传递给JVM的参数
jps失效
在定位问题过程会遇到这样一种情况,用jps查看不到进程id,用ps -ef | grep java却能看到启动的java进程。
要解释这种现象,先来了解下jps的实现机制:
java程序启动后,会在目录/tmp/hsperfdata_{userName}/下生成几个文件,文件名就是java进程的pid,因此jps列出进程id就是把这个目录下的文件名列一下而已,至于系统参数,则是读取文件中的内容。
我们来思考下:如果由于磁盘满了,无法创建这些文件,或者用户对这些文件没有读的权限。又或者因为某种原因这些文件或者目录被清除,出现以上这些情况,就会导致jps命令失效。
如果jps命令失效,而我们又要获取pid,还可以使用以下两种方法:
top | grep javaps -ef |grep java
jinfo
查看指定pid的所有JVM信息。
- jinfo -flags pid :查询虚拟机运行参数信息。
- jinfo -flag name pid :查询具体参数信息,如jinfo -flag UseSerialGC 42324,查看是否启用UseSerialGC。

jstack
主要用于生成指定进程当前时刻的线程快照,线程快照是当前java虚拟机每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是用于定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致长时间等待。
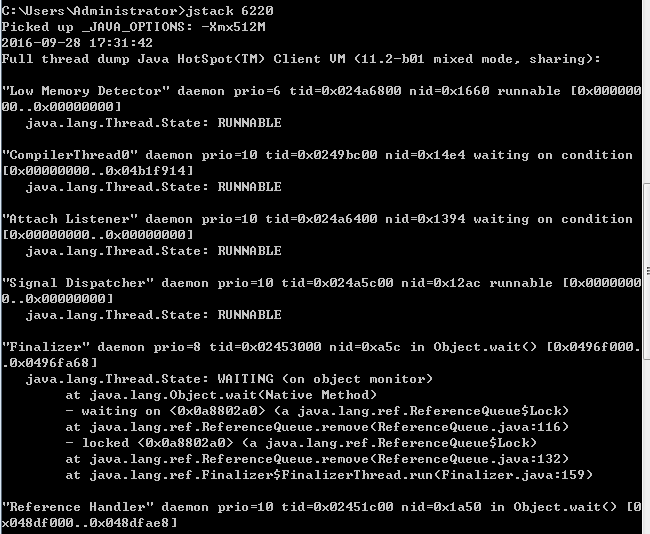
值得关注的线程状态有:
① 死锁:Deadlock(重点关注)
② 执行中:Runnable
③ 等待资源:Waiting on condition(重点关注)
④ 等待获取监视器:Waiting on monitor entry(重点关注)
⑤ 暂停:Suspended
⑥ 对象等待中:Object.wait() 或 TIMED_WAITING
⑦ 阻塞:Blocked(重点关注)
⑧ 停止:Parked
语法格式:1
jstack [option] pid
命令行参数选项说明如下:
- -l:long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况。
- -m:mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)。
应用示例
jstack可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。下面我们来一个实例找出某个Java进程中最耗费CPU的Java线程并定位堆栈信息。
先找出Java进程ID,我部署在服务器上的Java应用名称为mrf-center:
1
2root@ubuntu:/# ps -ef | grep mrf-center | grep -v grep
root 21711 1 1 14:47 pts/3 00:02:10 java -jar mrf-center.jar得到进程ID为21711。
使用
top -Hp pid命令找出该进程内最耗费CPU的线程
TIME列就是各个Java线程耗费的CPU时间,CPU时间最长的是线程ID为21742的线程,用
1
printf "%x\n" 21742
得到21742的十六进制值为54ee,下面会用到。
下面就要使用jstack命令了,用它来输出进程21711的堆栈信息,然后根据线程ID的十六进制值grep,如下:
1
2root@ubuntu:/# jstack 21711 | grep 54ee
"PollIntervalRetrySchedulerThread" prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait() [0x00007f94c6eda000]可以看到CPU消耗在
PollIntervalRetrySchedulerThread这个类的Object.wait(),我找了下我的代码,定位到下面的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// Idle wait
getLog().info("Thread [" + getName() + "] is idle waiting...");
schedulerThreadState = PollTaskSchedulerThreadState.IdleWaiting;
long now = System.currentTimeMillis();
long waitTime = now + getIdleWaitTime();
long timeUntilContinue = waitTime - now;
synchronized(sigLock) {
try {
if(!halted.get()) {
sigLock.wait(timeUntilContinue);
}
}
catch (InterruptedException ignore) {
}
}它是轮询任务的空闲等待代码,上面的
sigLock.wait(timeUntilContinue)就对应了前面的Object.wait()。
jstack另一个常见的用法是统计不同状态的线程数量,命令如下:1
jstack ${PID} | grep 'java.lang.Thread.State' |awk '{print $2}' |sort|uniq -c
jmap
jamp命令主要用于获取jvm的堆内存细节。从而可以离线分析堆,以检查内存泄漏,检查一些严重影响性能的大对象的创建,检查系统中什么对象最多,各种对象所占内存的大小等等。
jmap -heap pid
查看堆使用情况
jmap -histo pid
查看堆中对象数量和大小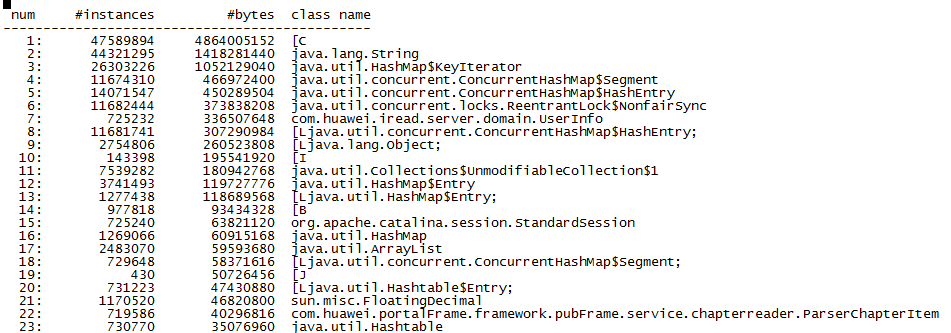
打印的信息分别是:序列号、对象的数量、这些对象的内存占用大小、这些对象所属的类的全限定名。
如果是内部类,类名的开头会加上*,如果加上live子参数的话,如jmap -histo:live pid,这个命令会触发一次FUll GC,只统计存活对象。
小技巧:
- 如果对象类型太多,可使用less查看,比如:如:
jmap -histo:live 19931 | less - 可采用
jmap -histo pid > a.txt将其不同时刻的统计数据保存到文件中,在一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。
jmap -dump:format=b,file=文件名 pid
将堆内存使用的详细情况输出到文件
将文件下载到本地后,然后使用jhat命令查看该文件:jhat -port 4000 文件名 ,在浏览器中访问 http://localhost:4000/ 查看。或者也可以使用可视化工具MAT来分析这个本地文件。
总结:jmap命令适用的场景是程序内存不足或者GC频繁,这时候很可能是内存泄漏。通过用以上命令查看堆使用情况、大量对象被持续引用等情况。
jstat
主要是对java应用程序的资源和性能进行实时的命令行监控,包括了对堆内存的使用和垃圾回收状况的监控。
语法格式:1
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
- option:我们经常使用的选项有gc、gcutil
- vmid:java进程id
- interval:间隔时间,单位默认为毫秒,也可指定为秒(s)。
- count:打印次数,可选。
jstat -gc PID 5000 3

- S0C:新生代幸存者0区的总容量(字节)
- S1C:新生代幸存者1区的总容量(字节)
- S0U:新生代幸存者0区已使用的容量(字节)
- S1U:新生代幸存者1区已使用的容量(字节)
- EC:新生代中Eden的空间(字节)
- EU:新生代中Eden已使用的空间(字节)
- OC:老年代的容量(字节)
- OU:老年代中已使用的空间(字节)
- PC:永久代的容量
- PU:永久代已使用的容量
- YGC:从应用程序启动到采样时年轻代中GC的次数
- YGCT:从应用程序启动到采样时年轻代中GC所使用的时间(单位:S)
- FGC:从应用程序启动到采样时老年代中GC(FULL GC)的次数
- FGCT:从应用程序启动到采样时老年代中GC所使用的时间(单位:S)
- GCT:从应用程序启动到采样时GC和FULL GC所使用的总时间(单位:S)
如果持续监控,则打印次数的参数可以省略:jstat -gc PID 5s。
jstat -gcutil PID 5000 3
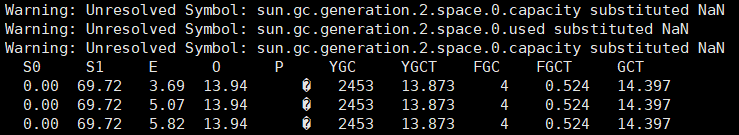
- s0:新生代中幸存者0区已使用的占当前容量百分比
- s1:新生代中幸存者1区已使用的占当前容量百分比
- E:新生代中Eden已使用的占当前容量百分比
- O:老年代中已使用的占当前容量百分比
- P:永久代中已使用的占当前容量百分比
jhat
主要用来解析java堆dump并启动一个web服务器,然后就可以在浏览器中查看堆的dump文件了。
生成dump文件的方法前面已经介绍了,此处主要介绍如何解析java堆转储文件,并启动一个web server。
jhat dump文件名

这个命令将dump文件转换成html格式,并且启动一个http服务,默认端口为7000。
如果端口冲突,可以使用以下命令指定端口:jhat -port 4000 heapdump,然后再浏览器中打开 http://localhost:端口号/ 访问,得到如下页面。