Redis集群有三种模式:主从复制模式、哨兵模式和集群模式。
主从模式(Master-Slave)
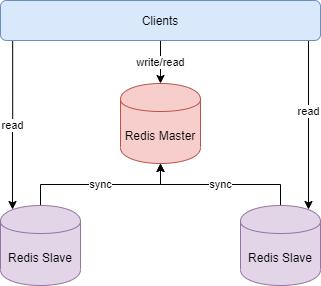
主从复制模式中包含一个主数据库实例(master)与一个或多个从数据库实例(slave)。master支持数据的写入和读取操作,而slave支持读取操作。slave会同步master的数据,即master上的数据在每个slave上也会保存一份。
配置预启动
- master实例不需要做特殊配置。
- slave实例需要配置
slaveof,指定master的ip和端口。
slave实例可以在运行时使用slaveof ip port命令,切换为新指定的master。 执行slaveof no one会把自己变成master实例。 - 执行
./redis-server /usr/local/redis/redis.conf启动所有实例。 - 启动后可以通过
info replecation查看实例的信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# redis-cli -h 192.168.30.128 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
192.168.30.128:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.30.129,port=6379,state=online,offset=168,lag=1
slave1:ip=192.168.30.130,port=6379,state=online,offset=168,lag=1
master_replid:fb4941e02d5032ad74c6e2383211fc58963dbe90
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:168
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:168
复制原理
流程
- 当slave实例启动后,会向master实例发送
SYNC或PSYNC指令。 - master实例接受到指令后,会执行
BGSAVE命令,生成 RDB 快照文件,并使用缓存区记录从现在开始的所有写命令。 - RDB 快照文件生成完成后,master会将其发送给slave。
- slave实例载入 RDB 文件,将自己的数据库状态同步更新为master执行
BGSAVE命令时的状态。 - master将缓冲区的所有写命令发送给salve,salve将执行这些写命令,数据库状态同步为主服务器最新状态。
SYNC 与 PSYNC 的区别
当主从同步完成后,如果此时从服务器宕机了一段时间,重新上线后势必要重新同步一下主服务器,SYNC与 PSYNC命令的区别就在于断线后重复制阶段处理的方式不同。
SYNC:从服务器重新向主服务器发起 SYNC命令,主服务器将所有数据再次重新生成 RDB 快照发给从服务器开始同步
PSYNC:从服务器重新向主服务器发起 PSYNC命令。主服务器根据双方数据的偏差量判断是否是需要完整重同步还是仅将断线期间执行过的写命令发给从服务器。
明显可以发先PSYNC相比SYNC效率好很多,要知道同步所有数据是一个非常费资源(磁盘 IO,网络)的操作,而如果只是因为短暂网络不稳定就同步所有资源是非常不值的。因此 Redis 在 2.8 版本后都开始使用PSYNC进行复制。
优缺点
优点
- 主从模式对数据做了备份,如果master实例出现问题,可以通过slave恢复大部分数据。
- 读写分离,提高了redis服务的并发量。
缺点
- 不具备自动容错和恢复功能:master实例宕机后,需要手动重启master或者重新指定master才能恢复写入功能。
- 缺少水平扩容的能力,当数据量很大时一个master可能会容量不够。
实际上,生产环境基本不会使用主从复制模式,但哨兵模式和集群模式下数据的同步依然是主从复制的模式,因此可以说主从复制是Redis高可用的基础。
哨兵模式(Sentinel)
主从复制模式中,master实例宕机后,需要人工手动处理才能恢复服务。Redis 2.8后,哨兵(Sentinel)模式解决了这一问题,哨兵模式可以实现自动化的系统监控和故障恢复(主从切换)功能。 Sentinel主要由两个作用:1)监控master和所有的slave是否正常运行;2)master出现故障时自动将slave转换为master。
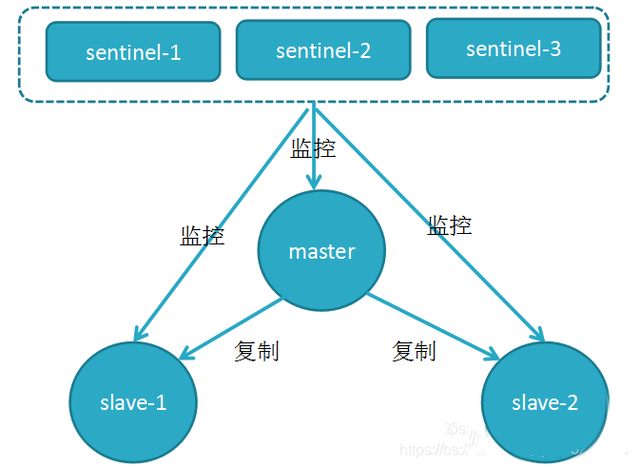
Sentinel (哨兵)其实就是运行在特殊模式下的redis服务器,哨兵模式中,Sentinel 的数量必须是奇数(2n+1)个。
哨兵的配置与启动
在Redis安装目录下有一个sentinel.conf文件,这个就是哨兵的配置文件。修改配置文件:1
2
3
4
5
6
7
8# vim /usr/local/redis/sentinel.conf
daemonize yes
logfile "/usr/local/redis/sentinel.log"
dir "/usr/local/redis/sentinel" #sentinel工作目录
sentinel monitor mymaster 192.168.30.128 6379 2 #判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数,mymaster是redis服务的名称(用户自定义)
sentinel auth-pass mymaster 123456 #mymaster是服务名称,123456是Redis服务密码
sentinel down-after-milliseconds mymaster 30000 #判断master主观下线时间,默认30s
这里需要注意,sentinel auth-pass mymaster 123456需要配置在sentinel monitor mymaster 192.168.30.128 6379 2下面,否则启动报错:1
2
3
4
5
6# /usr/local/bin/redis-sentinel /usr/local/redis/sentinel.conf
*** FATAL CONFIG FILE ERROR ***
Reading the configuration file, at line 104
>>> 'sentinel auth-pass mymaster 123456'
No such master with specified name.
执行./redis-sentinel /usr/local/redis/sentinel.conf启动sentinel。然后就可以通过sentinel的日志查看集群变化。集群中的实例仍然可以通过info replecation命令查看身份。
原理
网络连接
对于每个被Sentinel监视的master来说,Sentinel会创建两个连向master的异步网络连接:一个是命令连接,这个连接专门用于master发送命令,并接收命令回复。另一个是订阅连接,这个连接专门用于订阅master的_sentinel : _hello频道。
INFO命令
Sentinel默认会以每十秒一次的频率,通过命令连接向被监视的master发送INFO命令,通过分析master返回的命令回复,Sentinel可以获取以下两方面的信息:
一方面是关于master本身的信息,包括run_id域记录的服务器运行ID,以及role域记录的服务器角色,用于对master的实例结构进行更新。
另一方面是关于master属下所有slave的信息(ip+port),当Sentinel发现master下有新的从服务器出现时,Sentinel除了会为这个新的slave创建相应的实例结构之外,Sentinel还会创建连接到slave的命令连接和订阅连接(从服务器自动发现)。
hello命令
在默认情况下,Sentinel会以每两秒一次的频率,通过命令连接向所有被监视的master和slave发送一条命令,这条命令向服务器的sentinel: hello频道发送了一条信息,信息内容包括该sentinel和master的基本信息。该信息会被监视同一个服务器的Sentinel通过订阅连接接收到(包括发送命令的Sentinel自身),这些信息会被用于更新其他Sentinel对发送信息Sentinel的认知,也会被用于更新其他Sentinel对被监视服务器的认知。
当Sentinel通过频道信息发现一个新的Sentinel时,还会创建一个连向新Sentinel的命令连接,而新Sentinel也同样会创建连向这个Sentinel的命令连接,最终监视同一主服务器的多个Sentinel将形成相互连接的网络。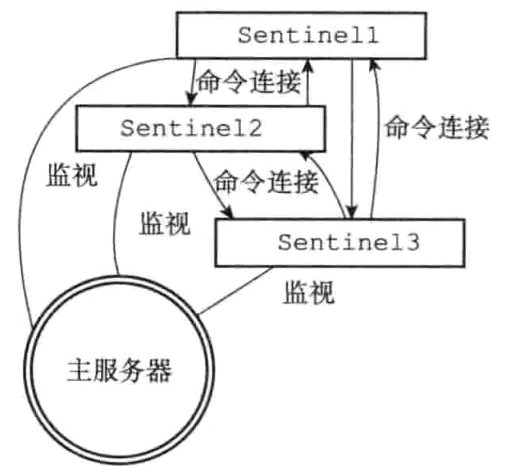
主观下线
在默认情况下,Sentinel会以每秒一次的频率向所有与它创建了命令连接的实例(包括主服务器、从服务器、其他Sentinel在内)发送PING命令,并通过实例返回的PING命令回复来判断实例是否在线。如果一个实例在down-after-milliseconds毫秒内(可配置),连续向Sentinel返回无效回复,那么Sentinel会修改这个实例所对应的实例结构,以此来表示这个实例已经进入主观下线状态。注意,多个Sentinel设置的主观下线时长可能不同。
客观下线
当Sentinel将一个主服务器判断为主观下线之后,为了确认这个主服务器是否真的下线了,它会向同样监视这一主服务器的其他Sentinel进行询问,看它们是否也认为主服务器已经进人了下线状态(可以是主观下线或者客观下线)。当Sentinel从其他Sentinel那里接收到足够数量(数量可配置)的已下线判断之后,Sentinel就会将从服务器判定为客观下线,并对主服务器执行故障转移操作。注意,不同Sentinel判断客观下线的条件可能不同。
故障转移
当一个master被判断为客观下线时,监视这个下线master的各个Sentinel会进行协商,选举出一个领头Sentinel,并由领头Sentinel对下线master执行故障转移操作。
该操作包含以下三个步骤:
- 在已下线master属下的所有从服务器里面,挑选出一个从服务器,并将其转换为master。
- 让已下线master属下的所有从服务器改为复制新的master。
- 将已下线master设置为新的master的从服务器,当这个旧的master重新上线时,它就会成为新的master的从服务器。
优缺点
优点
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
- 主从可以自动切换,系统更健壮,可用性更高。
缺点
- 仍然缺少水平扩容的能力。
- 写入都通过master实例,存在性能瓶颈。
集群模式(Cluster)
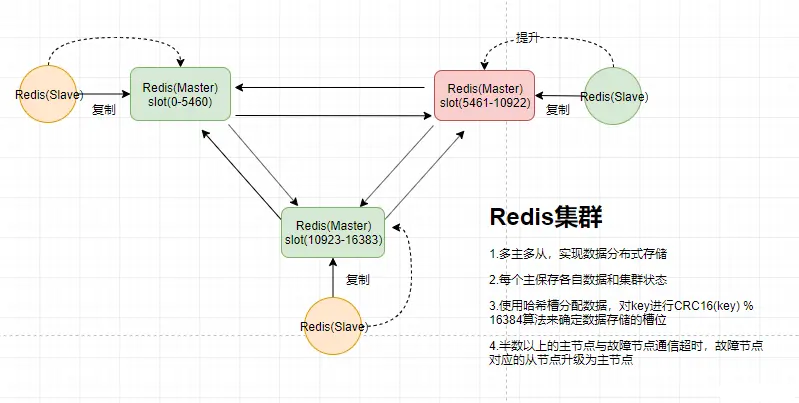
Redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台Redis服务器都存储相同的数据,但单台服务器的容量是有限的,所以在Redis 3.0版本开始加入了cluster模式,实现的Redis的分布式存储,也就是说Redis每台实例上存储不同的内容。集群模式下每个redis实例被称为节点(Node)。集群模式采用了无中心节点的方式来实现,每个主节点都会与其它主节点保持连接。节点间通过gossip协议交换彼此的信息,同时每个主节点又有一个或多个从节点。每个节点会保存一份数据分布表,节点会将自己的slot信息发送给其他节点,节点间不停的传递数据分布表,我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
配置与启动
修改redis.conf文件中的集群相关配置。1
2
3cluster-enabled yes #开启集群
cluster-config-file nodes_7001.conf #集群配置文件名,每个实例配置的要不同,redis会根据文件名自动创建该文件
cluster-node-timeout 15000 #节点不可用的超时时间,达到时间后该节点将被任务已宕机
至于实例的身份是master还是slave则不需要配置,集群会自动分配身份。
要创建集群,先执行./redis-server /usr/local/redis/redis.conf命令启动每个节点,然后执行下面的命令将节点构建为一个集群。1
redis-cli -a 123456 --cluster create 192.168.30.128:7001 192.168.30.128:7002 192.168.30.129:7003 192.168.30.129:7004 192.168.30.130:7005 192.168.30.130:7006 --cluster-replicas 1 #集群的密码是123456,副本数为1,即每个master有1个slave
控制台需要再次确认:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# redis-cli -a 123456 --cluster create 192.168.30.128:7001 192.168.30.128:7002 192.168.30.129:7003 192.168.30.129:7004 192.168.30.130:7005 192.168.30.130:7006 --cluster-replicas 1
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.30.129:7004 to 192.168.30.128:7001
Adding replica 192.168.30.130:7006 to 192.168.30.129:7003
Adding replica 192.168.30.128:7002 to 192.168.30.130:7005
M: 80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001
slots:[0-5460] (5461 slots) master
S: b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002
replicates 6788453ee9a8d7f72b1d45a9093838efd0e501f1
M: 4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003
slots:[5461-10922] (5462 slots) master
S: b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004
replicates 80c80a3f3e33872c047a8328ad579b9bea001ad8
M: 6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005
slots:[10923-16383] (5461 slots) master
S: 277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006
replicates 4d74ec66e898bf09006dac86d4928f9fad81f373
Can I set the above configuration? (type 'yes' to accept): yes #输入yes,接受上面配置
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
注意:在Redis 5.0后建立集群统一使用redis-cli,以前的版本使用redis-trib.rb,并且需要安装ruby软件相对复杂,所以Redis 5.0后的操作更加简单便捷了,如果使用redis-trib.rb创建集群的方式如下:1
redis-trib.rb create -a 123456 --replicas 1 192.168.30.128:7001 192.168.30.128:7002 192.168.30.129:7003 192.168.30.129:7004 192.168.30.130:7005 192.168.30.130:7006
然后可以看到自动生成nodes.conf文件:1
2
3
4
5
6
7
8
9
10
11
12# ls /data/redis/cluster/redis_7001/
appendonly.aof dump.rdb nodes-7001.conf
# vim /data/redis/cluster/redis_7001/nodes-7001.conf
6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005@17005 master - 0 1557454406312 5 connected 10923-16383
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557454407000 6 connected
b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002@17002 slave 6788453ee9a8d7f72b1d45a9093838efd0e501f1 0 1557454408371 5 connected
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 myself,master - 0 1557454406000 1 connected 0-5460
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557454407366 4 connected
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 master - 0 1557454407000 3 connected 5461-10922
vars currentEpoch 6 lastVoteEpoch 0
登陆集群:1
./redis-cli -c -h 192.168.30.128 -p 7001 -a 123456 # -c,使用集群方式登录
查看集群信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18192.168.30.128:7001> CLUSTER INFO #集群状态
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:580
cluster_stats_messages_pong_sent:551
cluster_stats_messages_sent:1131
cluster_stats_messages_ping_received:546
cluster_stats_messages_pong_received:580
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:1131
列出节点信息:1
2
3
4
5
6
7
8192.168.30.128:7001> CLUSTER NODES #列出节点信息
6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005@17005 master - 0 1557455176000 5 connected 10923-16383
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557455174000 6 connected
b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002@17002 slave 6788453ee9a8d7f72b1d45a9093838efd0e501f1 0 1557455175000 5 connected
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 myself,master - 0 1557455175000 1 connected 0-5460
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557455174989 4 connected
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 master - 0 1557455175995 3 connected 5461-10922
写入数据:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21192.168.30.128:7001> set key111 aaa
-> Redirected to slot [13680] located at 192.168.30.130:7005 #说明数据到了192.168.30.130:7005上
OK
192.168.30.130:7005> set key222 bbb
-> Redirected to slot [2320] located at 192.168.30.128:7001 #说明数据到了192.168.30.128:7001上
OK
192.168.30.128:7001> set key333 ccc
-> Redirected to slot [7472] located at 192.168.30.129:7003 #说明数据到了192.168.30.129:7003上
OK
192.168.30.129:7003> get key111
-> Redirected to slot [13680] located at 192.168.30.130:7005
"aaa"
192.168.30.130:7005> get key333
-> Redirected to slot [7472] located at 192.168.30.129:7003
"ccc"
192.168.30.129:7003>
可以看出redis cluster集群是去中心化的,每个节点都是平等的,连接哪个节点都可以获取和设置数据。
当然,平等指的是master节点,因为slave节点根本不提供服务,只是作为对应master节点的一个备份。
增加节点:
192.168.30.129上增加一节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# cp /usr/local/redis/cluster/redis_7003.conf /usr/local/redis/cluster/redis_7007.conf
# vim /usr/local/redis/cluster/redis_7007.conf
bind 192.168.30.129
port 7007
daemonize yes
pidfile "/var/run/redis_7007.pid"
logfile "/usr/local/redis/cluster/redis_7007.log"
dir "/data/redis/cluster/redis_7007"
#replicaof 192.168.30.129 6379
masterauth "123456"
requirepass "123456"
appendonly yes
cluster-enabled yes
cluster-config-file nodes_7007.conf
cluster-node-timeout 15000
# mkdir /data/redis/cluster/redis_7007
# chown -R redis:redis /usr/local/redis && chown -R redis:redis /data/redis
# redis-server /usr/local/redis/cluster/redis_7007.conf
192.168.30.130上增加一节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# cp /usr/local/redis/cluster/redis_7005.conf /usr/local/redis/cluster/redis_7008.conf
# vim /usr/local/redis/cluster/redis_7007.conf
bind 192.168.30.130
port 7008
daemonize yes
pidfile "/var/run/redis_7008.pid"
logfile "/usr/local/redis/cluster/redis_7008.log"
dir "/data/redis/cluster/redis_7008"
#replicaof 192.168.30.130 6379
masterauth "123456"
requirepass "123456"
appendonly yes
cluster-enabled yes
cluster-config-file nodes_7008.conf
cluster-node-timeout 15000
# mkdir /data/redis/cluster/redis_7008
# chown -R redis:redis /usr/local/redis && chown -R redis:redis /data/redis
# redis-server /usr/local/redis/cluster/redis_7008.conf
集群中增加节点:1
2
3
4
5
6
7
8
9
10
11
12192.168.30.129:7003> CLUSTER MEET 192.168.30.129 7007
OK
192.168.30.129:7003> CLUSTER NODES
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 myself,master - 0 1557457361000 3 connected 5461-10922
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 master - 0 1557457364746 1 connected 0-5460
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557457362000 6 connected
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557457363000 4 connected
b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002@17002 slave 6788453ee9a8d7f72b1d45a9093838efd0e501f1 0 1557457362000 5 connected
e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 192.168.30.129:7007@17007 master - 0 1557457362729 0 connected
6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005@17005 master - 0 1557457363739 5 connected 10923-16383
1 | 192.168.30.129:7003> CLUSTER MEET 192.168.30.130 7008 |
可以看到,新增的节点都是以master身份加入集群的。
更换节点身份:
将新增的192.168.30.130:7008节点身份改为192.168.30.129:7007的slave:1
./redis-cli -c -h 192.168.30.130 -p 7008 -a 123456 cluster replicate e51ab166bc0f33026887bcf8eba0dff3d5b0bf14
cluster replicate后面跟node_id,更改对应节点身份。也可以登入集群更改:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# redis-cli -c -h 192.168.30.130 -p 7008 -a 123456
192.168.30.130:7008> CLUSTER REPLICATE e51ab166bc0f33026887bcf8eba0dff3d5b0bf14
OK
192.168.30.130:7008> CLUSTER NODES
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557458316881 3 connected
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 master - 0 1557458314864 1 connected 0-5460
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 master - 0 1557458316000 3 connected 5461-10922
6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005@17005 master - 0 1557458315872 5 connected 10923-16383
b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002@17002 slave 6788453ee9a8d7f72b1d45a9093838efd0e501f1 0 1557458317890 5 connected
1a1c7f02fce87530bd5abdfc98df1cffce4f1767 192.168.30.130:7008@17008 myself,slave e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 0 1557458315000 7 connected
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557458315000 1 connected
e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 192.168.30.129:7007@17007 master - 0 1557458314000 0 connected
查看相应的nodes.conf文件,可以发现有更改,它记录当前集群的节点信息。1
2
3
4
5
6
7
8
9
10
11# cat /data/redis/cluster/redis_7001/nodes-7001.conf
1a1c7f02fce87530bd5abdfc98df1cffce4f1767 192.168.30.130:7008@17008 slave e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 0 1557458236169 7 connected
6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005@17005 master - 0 1557458235000 5 connected 10923-16383
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557458234103 6 connected
b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002@17002 slave 6788453ee9a8d7f72b1d45a9093838efd0e501f1 0 1557458235129 5 connected
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 myself,master - 0 1557458234000 1 connected 0-5460
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557458236000 4 connected
e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 192.168.30.129:7007@17007 master - 0 1557458236000 0 connected
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 master - 0 1557458233089 3 connected 5461-10922
vars currentEpoch 7 lastVoteEpoch 0
删除节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31192.168.30.130:7008> CLUSTER FORGET 1a1c7f02fce87530bd5abdfc98df1cffce4f1767
(error) ERR I tried hard but I can't forget myself... #无法删除登录节点
192.168.30.130:7008> CLUSTER FORGET e51ab166bc0f33026887bcf8eba0dff3d5b0bf14
(error) ERR Can't forget my master! #不能删除自己的master节点
192.168.30.130:7008> CLUSTER FORGET 6788453ee9a8d7f72b1d45a9093838efd0e501f1
OK #可以删除其它的master节点
192.168.30.130:7008> CLUSTER NODES
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557458887328 3 connected
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 master - 0 1557458887000 1 connected 0-5460
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 master - 0 1557458886000 3 connected 5461-10922
b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002@17002 slave - 0 1557458888351 5 connected
1a1c7f02fce87530bd5abdfc98df1cffce4f1767 192.168.30.130:7008@17008 myself,slave e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 0 1557458885000 7 connected
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557458883289 1 connected
e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 192.168.30.129:7007@17007 master - 0 1557458885310 0 connected
192.168.30.130:7008> CLUSTER FORGET b4d3eb411a7355d4767c6c23b4df69fa183ef8bc
OK #可以删除其它的slave节点
192.168.30.130:7008> CLUSTER NODES
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557459031397 3 connected
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 master - 0 1557459032407 1 connected 0-5460
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 master - 0 1557459035434 3 connected 5461-10922
6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005@17005 master - 0 1557459034000 5 connected 10923-16383
1a1c7f02fce87530bd5abdfc98df1cffce4f1767 192.168.30.130:7008@17008 myself,slave e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 0 1557459032000 7 connected
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 slave 80c80a3f3e33872c047a8328ad579b9bea001ad8 0 1557459034000 1 connected
e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 192.168.30.129:7007@17007 master - 0 1557459034427 0 connected
模拟master节点挂掉:1
2
3
4
5# netstat -lntp |grep 7001
tcp 0 0 192.168.30.128:17001 0.0.0.0:* LISTEN 6701/redis-server 1
tcp 0 0 192.168.30.128:7001 0.0.0.0:* LISTEN 6701/redis-server 1
# kill 6701
1 | 192.168.30.130:7008> CLUSTER NODES |
对应7001的一行可以看到,master fail,状态为disconnected;而对应7004的一行,slave已经变成master。
重新启动7001节点:1
2
3
4
5
6
7
8
9
10
11
12# redis-server /usr/local/redis/cluster/redis_7001.conf
192.168.30.130:7008> CLUSTER NODES
277daeb8660d5273b7c3e05c263f861ed5f17b92 192.168.30.130:7006@17006 slave 4d74ec66e898bf09006dac86d4928f9fad81f373 0 1557461307000 3 connected
80c80a3f3e33872c047a8328ad579b9bea001ad8 192.168.30.128:7001@17001 slave b6331cbc986794237c83ed2d5c30777c1551546e 0 1557461305441 8 connected
4d74ec66e898bf09006dac86d4928f9fad81f373 192.168.30.129:7003@17003 master - 0 1557461307962 3 connected 5461-10922
6788453ee9a8d7f72b1d45a9093838efd0e501f1 192.168.30.130:7005@17005 master - 0 1557461304935 5 connected 10923-16383
b4d3eb411a7355d4767c6c23b4df69fa183ef8bc 192.168.30.128:7002@17002 slave 6788453ee9a8d7f72b1d45a9093838efd0e501f1 0 1557461306000 5 connected
1a1c7f02fce87530bd5abdfc98df1cffce4f1767 192.168.30.130:7008@17008 myself,slave e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 0 1557461305000 7 connected
b6331cbc986794237c83ed2d5c30777c1551546e 192.168.30.129:7004@17004 master - 0 1557461308972 8 connected 0-5460
e51ab166bc0f33026887bcf8eba0dff3d5b0bf14 192.168.30.129:7007@17007 master - 0 1557461307000 0 connected
可以看到,7001节点启动后为slave节点,并且是7004的slave节点。即master节点如果挂掉,它的slave节点变为新master节点继续对外提供服务,而原来的master节点如果重启,则变为新master节点的slave节点。
另外,如果这里是拿7007节点做测试的话,会发现7008节点并不会切换,这是因为7007节点上根本没数据。集群数据被分为三份,采用哈希槽 (hash slot)的方式来分配16384个slot的话,它们三个节点分别承担的slot 区间是:1
2
3节点7004覆盖0-5460
节点7003覆盖5461-10922
节点7005覆盖10923-16383
SLOT
Redis集群存储数据是通过一种哈希槽(hash slot) 的方式来分配的。集群默认分配了16384(2的14次方)个slot,每个节点上都有一个插槽(slot)取值范围是0-16383。当存取数据时Redis会用CRC16算法来取模得到所属的slot,然后将这个key分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
当集群中加入新节点时,会与集群中的某个节点进行握手,该节点会把集群内的其它节点信息通过gossip协议发送给新节点,新节点与这些节点完成握手后加入到集群中。然后集群中的节点会各取一部分哈希槽分配给新节点。
容错机制
如果半数以上master节点与故障节点通信超过(cluster-node-timeout),认为该节点故障,自动触发故障转移操作。 故障节点对应的从节点自动升级为主节点,如果某个主挂掉,而没有从节点可以使用,那么整个Redis集群进入宕机状态。