基本介绍
synchronized 是Java语言中的一个关键字,它的作用就是保证多个线程可以安全地访问某个公共的资源。
synchronized在多线程编程中属于元老级角色,很多人都把它当做是一个重量级锁。但其实,随着JDK 1.6对synchronized进行了各种优化之后,有些情况下它会变得不那么重了。本文接下来将对synchronized作一些深入分析。
应用场景
首先我们需要知道synchronized实现同步的基础:Java中的每一个对象都可以作为锁,每一把锁在某个时刻最多只能被一个线程持有,持有锁的线程可以访问synchronized保护的资源(也就是可以执行synchronized保护的代码),而未获取到锁的线程只能阻塞等待当前线程释放目标锁。
synchronized应用场景有如下三种:
修饰实例方法,锁是当前实例对象。
1
2
3
4
5
6
7
8public synchronized void method1() {
log.info("线程{}获取到了锁", Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}修饰静态方法,锁是当前类的Class对象。
1
2
3
4
5
6
7
8public static synchronized void method2() {
log.info("线程{}获取到了锁", Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}修饰代码块,锁是Synchonized括号里配置的对象。即可以是Class对像,也可以是具体的实例对象,比如下面这三种情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
414j
public class SychronizedTest {
private static final Object obj = new Object();
public void blockTest1() {
synchronized (this) {
log.info("线程{}获取到了锁", Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void blockTest2() {
synchronized (obj) {
log.info("线程{}获取到了锁", Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void blockTest3() {
synchronized (SychronizedTest.class) {
log.info("线程{}获取到了锁", Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
synchronized原理
当一个线程试图访问synchronized修饰的代码时,它首先必须得到锁,退出或抛出异常时必须释放锁。那么锁到底存在哪里呢?锁里面会存储什么信息呢?
monitorenter和monitorexit
从JVM规范中可以看到Synchonized在JVM里的实现原理,JVM基于进入和退出Monitor对象来实现方法同步和代码块同步,但两者的实现细节不一样。代码块同步是使用monitorenter和monitorexit指令实现的,而方法同步是使用另外一种方式实现的,细节在JVM规范里并没有详细说明。但是,方法的同步同样还是可以使用这两个指令来实现。
monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处,JVM要保证每个monitorenter必须有对应的monitorexit与之配对。
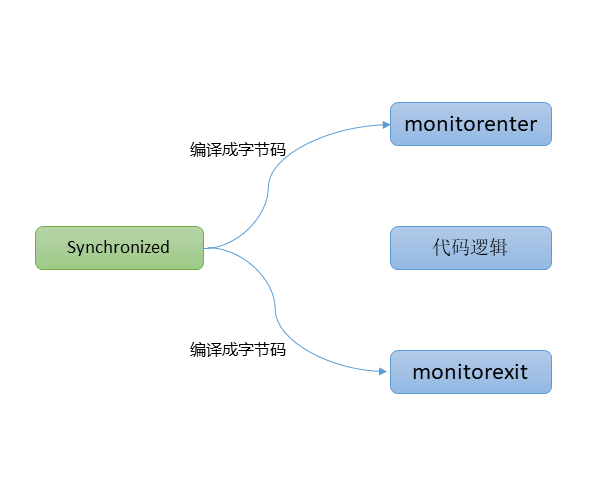
关于monitor对象,本文将在后面详细讨论。
monitorenter
首先我们来看一下JVM规范中对于monitorenter的描述。
文档地址:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html#jvms-6.5.monitorenter。
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows:
- If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor.
- If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count.
- If another thread already owns the monitor associated with objectref, the thread blocks until the monitor’s entry count is zero, then tries again to gain ownership.
翻译过来大概是说:
每一个对象都会和一个监视器monitor关联。监视器被占用时会被锁住,其他线程无法来获取该monitor。 当JVM执行某个线程的某个方法内部的monitorenter时,它会尝试去获取当前对象对应的monitor的所有权。其过程如下:
- 若monitor的进入数为0,线程可以进入monitor,并将monitor的进入数置为1。当前线程成为monitor的owner(所有者)。
- 若线程已拥有monitor的所有权,允许它重入monitor,重入后monitor的进入数加1。
- 若其他线程已经占有monitor的所有权,那么当前尝试获取monitor的所有权的线程会被阻塞,直到monitor的进入数变为0,才能重新尝试获取monitor的所有权。
monitorexit
我们再看一下JVM规范中对于monitorenter的描述。
文档地址:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html#jvms-6.5.monitorexit。
The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref.
The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.
翻译过来:
- 能执行monitorexit指令的线程一定是拥有当前对象的monitor的所有权的线程。
- 执行monitorexit时会将monitor的进入数减1。当monitor的进入数减为0时,当前线程退出monitor,不再拥有monitor的所有权,此时其他被这个monitor阻塞的线程可以尝试去获取这个monitor的所有权。
javap反汇编
JDK自带的一个工具:javap ,可以对字节码文件(.class文件)进行反汇编,查看字节码指令。比如对于如下同步代码块的示例代码。
1 | public class SychronizedDemo1 { |
在.class文件所在目录下,从命令行输入:1
javap -c SychronizedDemo1.class
可以查看字节码指令的信息。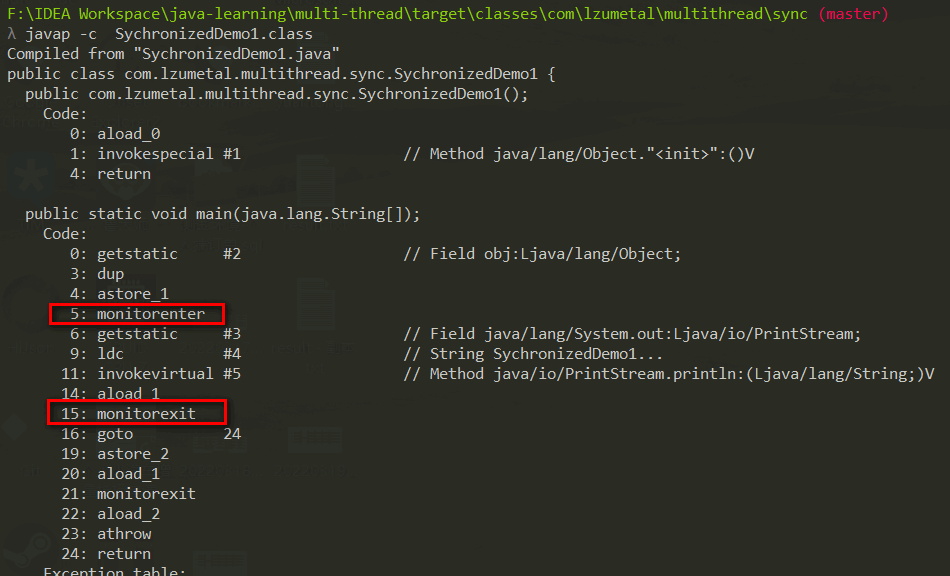
上面是同步代码块的反汇编,那么对于同步方法呢?比如对于如下同步方法的代码:1
2
3
4
5
6
7public class SychronizedDemo2 {
public synchronized void method1() {
System.out.println("SychronizedDemo2...");
}
}
使用javap -c -v SychronizedDemo1.class反汇编(注意此处多了-个-v参数),可以看到同步方法会增加 ACC_SYNCHRONIZED 修饰。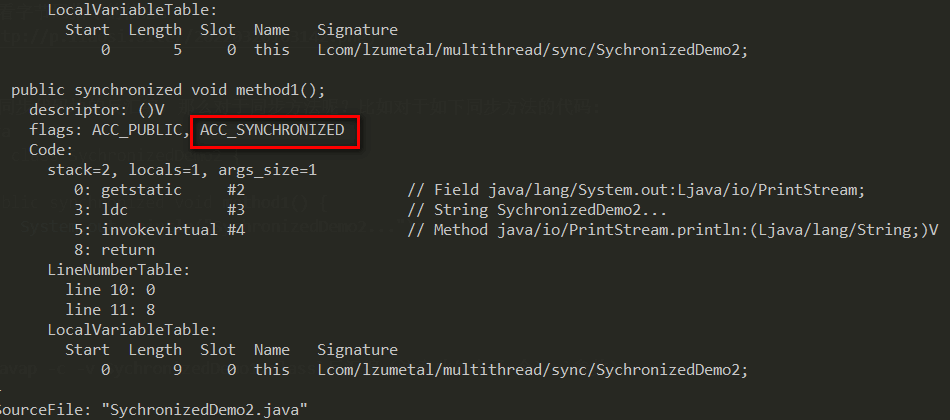
ACC_SYNCHRONIZED 的作用就是会隐式调用monitorenter和monitorexit,在执行同步方法前会调用monitorenter,在执行完同步方法或者方法抛出异常后会调用monitorexit。
官方文档上对此也有说明https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.11.10。
深入JVM源码
在前面介绍synchronized原理时,其线程安全的语义实现最终依赖一个叫monitor的对象,本小节将通过JVM源码进一步深入分析synchronized的原理,让我们看看monitor到底是什么。
下载JVM源码
通过如下简单几个步骤,下载jdk 1.8 JVM的源码压缩文件。
http://openjdk.java.net/ –> Mercurial –> jdk8 –> hotspot –> zip
下载完之后解压,然后用 Visual Studio Code 打开,我们知道JVM是用C++写的,所以 Visual Studio Code 安装一下C/C++的扩展包。
monitor(监视器)
在HotSpot虚拟机中,monitor是由ObjectMonitor实现的。ObjectMonitor类位于HotSpot虚拟机源码ObjectMonitor.hpp文件中(src/share/vm/runtime/objectMonitor.hpp)。ObjectMonitor主要数据结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// initialize the monitor, exception the semaphore, all other fields
// are simple integers or pointers
ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; // 线程的重入次数
_object = NULL; // 存储该monitor的对象
_owner = NULL; // 标识拥有该monitor的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; // 多线程竞争锁时的单向列表
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
- _owner:初始时为NULL。当有线程占有该monitor时,owner标记为该线程的唯一标识。当线程释放monitor时,owner又恢复为NULL。owner是一个临界资源,JVM是通过CAS操作来保证其线程安全的。
- _cxq:竞争队列,所有请求锁的线程首先会被放在这个队列中(单向链接)。_cxq是一个临界资源,JVM通过CAS原子指令来修改_cxq队列。修改前_cxq的旧值填入了node的next字段,_cxq指向新值(新线程)。因此_cxq是一个后进先出的stack(栈)。
- _EntryList:_cxq队列中有资格成为候选资源的线程会被移动到该队列中。
- _WaitSet:因为调用wait方法而被阻塞的线程会被放在该队列中。
ObjectMonitor中的数据结构:_owner、_WaitSet和_EntryList,它们之间的关系转换可以用下图表示。
对于monitor对象的小总结:
每一个锁对象都会关联一个monitor对象(监视器,它才是真正的锁对象),当一个线程想要执行一段被synchronized修饰的同步方法或者代码块时,该线程得先获取到Java对象对应的monitor。monitor对象内部有两个重要的成员变量,owner会保存获得锁的线程,recursions会保存线程获得锁的次数,当执行到monitorexit时,recursions会-1,当计数器减到0时,这个线程就会释放锁。
我们的Java代码里不会显示地去创造这么一个monitor对象,我们也无需创建,事实上可以这么理解:monitor并不是随着对象创建而创建的。我们是通过synchronized修饰符告诉JVM需要为我们的某个对象创建关联的monitor对象。每个线程都存在两个ObjectMonitor对象列表,分别为free和used列表。
同时JVM中也维护着global locklist。当线程需要ObjectMonitor对象时,首先从线程自身的free表中申请,若存在则使用,若不存在则从global list中申请。
monitor竞争
- 执行monitorenter时,会调用InterpreterRuntime.cpp(位于:src/share/vm/interpreter/interpreterRuntime.cpp) 的 InterpreterRuntime::monitorenter函数。具体代码可参见HotSpot源码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
thread->last_frame().interpreter_frame_verify_monitor(elem);
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),
"must be NULL or an object");
thread->last_frame().interpreter_frame_verify_monitor(elem);
IRT_END
2.对于重量级锁,monitorenter函数中会调用 ObjectSynchronizer::slow_enter函数。
3.最终调用 ObjectMonitor::enter函数(位于:src/share/vm/runtime/objectMonitor.cpp),源码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77void ATTR ObjectMonitor::enter(TRAPS) {
// The following code is ordered to check the most common cases first
// and to reduce RTS->RTO cache line upgrades on SPARC and IA32 processors.
Thread * const Self = THREAD ;
void * cur ;
// 通过CAS操作尝试把monitor的_owner字段设置为当前线程
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
// Either ASSERT _recursions == 0 or explicitly set _recursions = 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
// CONSIDER: set or assert OwnerIsThread == 1
return ;
}
// 线程重入,recursions++
if (cur == Self) {
// TODO-FIXME: check for integer overflow! BUGID 6557169.
_recursions ++ ;
return ;
}
// 如果当前线程是第一次进入该monitor,设置_recursions为1,_owner为当前线程
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ;
// Commute owner from a thread-specific on-stack BasicLockObject address to
// a full-fledged "Thread *".
_owner = Self ;
OwnerIsThread = 1 ;
return ;
}
//省略一些代码。。。
{ // Change java thread status to indicate blocked on monitor enter.
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
DTRACE_MONITOR_PROBE(contended__enter, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_enter()) {
JvmtiExport::post_monitor_contended_enter(jt, this);
}
OSThreadContendState osts(Self->osthread());
ThreadBlockInVM tbivm(jt);
Self->set_current_pending_monitor(this);
// TODO-FIXME: change the following for(;;) loop to straight-line code.
for (;;) {
jt->set_suspend_equivalent();
// cleared by handle_special_suspend_equivalent_condition()
// or java_suspend_self()
// 如果获取锁失败,则等待锁的释放;
EnterI (THREAD) ;
if (!ExitSuspendEquivalent(jt)) break ;
//
// We have acquired the contended monitor, but while we were
// waiting another thread suspended us. We don't want to enter
// the monitor while suspended because that would surprise the
// thread that suspended us.
//
_recursions = 0 ;
_succ = NULL ;
exit (false, Self) ;
jt->java_suspend_self();
}
Self->set_current_pending_monitor(NULL);
}
//省略一些代码。。。
}
此处省略锁的自旋优化等操作,统一放在后面synchronzied优化中说。以上enter函数代码的具体流程概括如下:
- 通过CAS尝试把monitor的owner字段设置为当前线程。
- 如果设置之前的owner指向当前线程,说明当前线程再次进入monitor,即重入锁,执行
recursions ++,记录重入的次数。 - 如果当前线程是第一次进入该monitor,设置recursions为1,_owner为当前线程,该线程成功获得锁并返回。
- 如果获取锁失败,则等待锁的释放。
monitor等待
竞争失败等待调用的是ObjectMonitor对象的EnterI方法(位于:src/share/vm/runtime/objectMonitor.cpp),源码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
assert (Self->is_Java_thread(), "invariant") ;
assert (((JavaThread *) Self)->thread_state() == _thread_blocked , "invariant") ;
// Try the lock - TATAS
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
DeferredInitialize () ;
// We try one round of spinning *before* enqueueing Self.
//
// If the _owner is ready but OFFPROC we could use a YieldTo()
// operation to donate the remainder of this thread's quantum
// to the owner. This has subtle but beneficial affinity
// effects.
if (TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
// The Spin failed -- Enqueue and park the thread ...
assert (_succ != Self , "invariant") ;
assert (_owner != Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
// 当前线程被封装成ObjectWaiter对象node,状态设置成ObjectWaiter::TS_CXQ
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
// Push "Self" onto the front of the _cxq.
// Once on cxq/EntryList, Self stays on-queue until it acquires the lock.
// Note that spinning tends to reduce the rate at which threads
// enqueue and dequeue on EntryList|cxq.
// 通过CAS把node节点push到_cxq列表中
ObjectWaiter * nxt ;
for (;;) {
node._next = nxt = _cxq ;
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
if (TryLock (Self) > 0) {
assert (_succ != Self , "invariant") ;
assert (_owner == Self , "invariant") ;
assert (_Responsible != Self , "invariant") ;
return ;
}
}
// 省略部分代码...
for (;;) {
// 线程在被挂起前做一下挣扎,看能不能获取到锁
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
// park self
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
// 通过park将当前线程挂起,等待被唤醒
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
if (TryLock(Self) > 0) break ;
// 省略部分代码。。。
}
// 省略部分代码。。。
}
当该线程被唤醒时,会从挂起的点继续执行,通过 ObjectMonitor::TryLock 方法尝试获取锁,TryLock方法实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int ObjectMonitor::TryLock (Thread * Self) {
for (;;) {
void * own = _owner ;
if (own != NULL) return 0 ;
if (Atomic::cmpxchg_ptr (Self, &_owner, NULL) == NULL) {
// Either guarantee _recursions == 0 or set _recursions = 0.
assert (_recursions == 0, "invariant") ;
assert (_owner == Self, "invariant") ;
// CONSIDER: set or assert that OwnerIsThread == 1
return 1 ;
}
// The lock had been free momentarily, but we lost the race to the lock.
// Interference -- the CAS failed.
// We can either return -1 or retry.
// Retry doesn't make as much sense because the lock was just acquired.
if (true) return -1 ;
}
}
以上代码的具体流程概括如下:
- 当前线程被封装成ObjectWaiter对象node,状态设置成ObjectWaiter::TS_CXQ。
- 在for循环中,通过CAS把node节点push到_cxq列表中,同一时刻可能有多个线程把自己的node节点push到_cxq列表中。
- node节点push到_cxq列表之后,通过自旋尝试获取锁,如果还是没有获取到锁,则通过park将当前线程挂起,等待被唤醒。
- 当该线程被唤醒时,会从挂起的点继续执行,通过 ObjectMonitor::TryLock 尝试获取锁。
monitor释放
当某个持有锁的线程执行完同步代码块时,会进行锁的释放,给其它线程机会执行同步代码,在HotSpot中,通过退出monitor的方式实现锁的释放,并通知被阻塞的线程,具体实现位于ObjectMonitor的exit方法中。(位于:src/share/vm/runtime/objectMonitor.cpp),源码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
Thread * Self = THREAD ;
// 省略部分代码。。。
//如果recursions大于0,则recursions自减1
if (_recursions != 0) {
_recursions--; // this is simple recursive enter
TEVENT (Inflated exit - recursive) ;
return ;
}
// 省略部分代码。。。
for (;;) {
// 省略部分代码。。。
ObjectWaiter * w = NULL ;
int QMode = Knob_QMode ;
// qmode = 2:直接绕过EntryList队列,从cxq队列中获取线程用于竞争锁
if (QMode == 2 && _cxq != NULL) {
// QMode == 2 : cxq has precedence over EntryList.
// Try to directly wake a successor from the cxq.
// If successful, the successor will need to unlink itself from cxq.
w = _cxq ;
assert (w != NULL, "invariant") ;
assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
ExitEpilog (Self, w) ;
return ;
}
// qmode =3:cxq队列插入EntryList尾部;
if (QMode == 3 && _cxq != NULL) {
// Aggressively drain cxq into EntryList at the first opportunity.
// This policy ensure that recently-run threads live at the head of EntryList.
// Drain _cxq into EntryList - bulk transfer.
// First, detach _cxq.
// The following loop is tantamount to: w = swap (&cxq, NULL)
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// Append the RATs to the EntryList
// TODO: organize EntryList as a CDLL so we can locate the tail in constant-time.
ObjectWaiter * Tail ;
for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next) ;
if (Tail == NULL) {
_EntryList = w ;
} else {
Tail->_next = w ;
w->_prev = Tail ;
}
// Fall thru into code that tries to wake a successor from EntryList
}
// qmode =4:cxq队列插入到_EntryList头部
if (QMode == 4 && _cxq != NULL) {
// Aggressively drain cxq into EntryList at the first opportunity.
// This policy ensure that recently-run threads live at the head of EntryList.
// Drain _cxq into EntryList - bulk transfer.
// First, detach _cxq.
// The following loop is tantamount to: w = swap (&cxq, NULL)
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// Prepend the RATs to the EntryList
if (_EntryList != NULL) {
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
// Fall thru into code that tries to wake a successor from EntryList
}
w = _EntryList ;
if (w != NULL) {
// I'd like to write: guarantee (w->_thread != Self).
// But in practice an exiting thread may find itself on the EntryList.
// Lets say thread T1 calls O.wait(). Wait() enqueues T1 on O's waitset and
// then calls exit(). Exit release the lock by setting O._owner to NULL.
// Lets say T1 then stalls. T2 acquires O and calls O.notify(). The
// notify() operation moves T1 from O's waitset to O's EntryList. T2 then
// release the lock "O". T2 resumes immediately after the ST of null into
// _owner, above. T2 notices that the EntryList is populated, so it
// reacquires the lock and then finds itself on the EntryList.
// Given all that, we have to tolerate the circumstance where "w" is
// associated with Self.
assert (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
// If we find that both _cxq and EntryList are null then just
// re-run the exit protocol from the top.
w = _cxq ;
if (w == NULL) continue ;
// Drain _cxq into EntryList - bulk transfer.
// First, detach _cxq.
// The following loop is tantamount to: w = swap (&cxq, NULL)
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
TEVENT (Inflated exit - drain cxq into EntryList) ;
assert (w != NULL , "invariant") ;
assert (_EntryList == NULL , "invariant") ;
// Convert the LIFO SLL anchored by _cxq into a DLL.
// The list reorganization step operates in O(LENGTH(w)) time.
// It's critical that this step operate quickly as
// "Self" still holds the outer-lock, restricting parallelism
// and effectively lengthening the critical section.
// Invariant: s chases t chases u.
// TODO-FIXME: consider changing EntryList from a DLL to a CDLL so
// we have faster access to the tail.
if (QMode == 1) {
// QMode == 1 : drain cxq to EntryList, reversing order
// We also reverse the order of the list.
ObjectWaiter * s = NULL ;
ObjectWaiter * t = w ;
ObjectWaiter * u = NULL ;
while (t != NULL) {
guarantee (t->TState == ObjectWaiter::TS_CXQ, "invariant") ;
t->TState = ObjectWaiter::TS_ENTER ;
u = t->_next ;
t->_prev = u ;
t->_next = s ;
s = t;
t = u ;
}
_EntryList = s ;
assert (s != NULL, "invariant") ;
} else {
// QMode == 0 or QMode == 2
_EntryList = w ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
}
// In 1-0 mode we need: ST EntryList; MEMBAR #storestore; ST _owner = NULL
// The MEMBAR is satisfied by the release_store() operation in ExitEpilog().
// See if we can abdicate to a spinner instead of waking a thread.
// A primary goal of the implementation is to reduce the
// context-switch rate.
if (_succ != NULL) continue;
w = _EntryList ;
if (w != NULL) {
guarantee (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
}
}
- 退出同步代码块时会让_recursions减1,当_recursions的值减为0时,说明线程释放了锁。
- 根据不同的策略(由QMode指定),从cxq或EntryList中获取头节点,通过ObjectMonitor::ExitEpilog 方法唤醒该节点封装的线程,唤醒操作最终由unpark完成,实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {
assert (_owner == Self, "invariant") ;
// Exit protocol:
// 1. ST _succ = wakee
// 2. membar #loadstore|#storestore;
// 2. ST _owner = NULL
// 3. unpark(wakee)
_succ = Knob_SuccEnabled ? Wakee->_thread : NULL ;
ParkEvent * Trigger = Wakee->_event ;
// Hygiene -- once we've set _owner = NULL we can't safely dereference Wakee again.
// The thread associated with Wakee may have grabbed the lock and "Wakee" may be
// out-of-scope (non-extant).
Wakee = NULL ;
// Drop the lock
OrderAccess::release_store_ptr (&_owner, NULL) ;
OrderAccess::fence() ; // ST _owner vs LD in unpark()
if (SafepointSynchronize::do_call_back()) {
TEVENT (unpark before SAFEPOINT) ;
}
DTRACE_MONITOR_PROBE(contended__exit, this, object(), Self);
Trigger->unpark() ; // 唤醒之前被pack()挂起的线程
// Maintain stats and report events to JVMTI
if (ObjectMonitor::_sync_Parks != NULL) {
ObjectMonitor::_sync_Parks->inc() ;
}
}
被唤醒的线程,会回到 void ATTR ObjectMonitor::EnterI (TRAPS) 的第600行,继续执行monitor的竞争。1
2
3
4
5
6
7
8
9
10
11
12
13// park self
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
if (TryLock(Self) > 0) break ;
monitor是重量级锁
可以看到ObjectMonitor的函数调用中会涉及到Atomic::cmpxchg_ptr,Atomic::inc_ptr等内核函数,执行同步代码块,没有竞争到锁的对象会park()被挂起,竞争到锁的线程会unpark()唤醒。这个时候就会存在操作系统用户态和内核态的转换,这种切换会消耗大量的系统资源。所以synchronized是Java语言中是一个重量级(Heavyweight)的操作。
JDK6 synchronized优化
锁的存放
当一个线程尝试访问synchronized修饰的代码时,它首先要获得锁,那么这个锁到底存在哪里呢?是存在锁对象的对象头中的。
对象头
在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。如下图所示: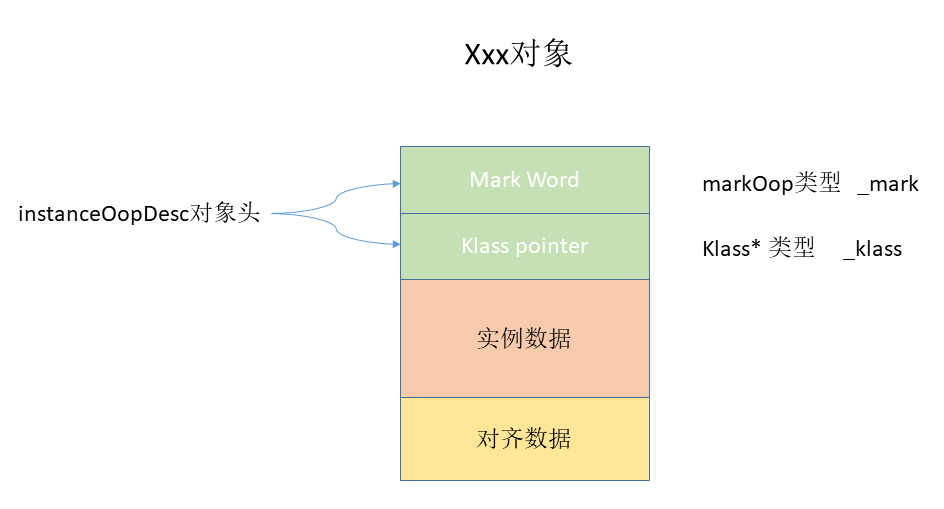
HotSpot采用instanceOopDesc和arrayOopDesc来描述对象头,arrayOopDesc对象用来描述数组类型。instanceOopDesc的定义的在Hotspot源码的 instanceOop.hpp 文件中(src/share/vm/oops/instanceOop.hpp),另外,arrayOopDesc的定义对应 arrayOop.hpp 文件(src/share/vm/oops/arrayOop.hpp)。
1 | class instanceOopDesc : public oopDesc { |
从instanceOopDesc代码中可以看到 instanceOopDesc继承自oopDesc,oopDesc的定义载Hotspot源码中的 oop.hpp 文件中(src/share/vm/oops/oop.hpp)。
1 | class oopDesc { |
在普通实例对象中,oopDesc的定义包含两个成员,分别是 _mark 和 _metadata。
_mark 表示对象标记、属于markOop类型,也就是接下来要讲解的Mark World,它记录了对象和锁有关的信息。_metadata 表示类元信息,类元信息存储的是对象指向它的类元数据(Klass)的首地址,其中Klass表示普通指针、 _compressed_klass 表示压缩类指针。
总结:对象头由两部分组成,一部分用于存储自身的运行时数据,称之为 Mark Word,另外一部分是类型指针,及对象指向它的类元数据的指针。
Mark Word
Mark Word用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机的位长一致。Mark Word对应的类型是 markOop 。源码位于 markOop.hpp 中。
在64位虚拟机下,Mark Word是64bit大小的,其存储结构如下:
在32位虚拟机下,Mark Word是32bit大小的,其存储结构如下:
klass pointer
这一部分用于存储对象的类型指针,该指针指向它的类元数据,JVM通过这个指针确定对象是哪个类的实例。该指针的位长度为JVM的一个字大小,即32位的JVM为32位,64位的JVM为64位。 如果应用的对象过多,使用64位的指针将浪费大量内存,统计而言,64位的JVM将会比32位的JVM多耗费50%的内存。为了节约内存可以使用选项-XX:+UseCompressedOops开启指针压缩,其中,oop即ordinary object pointer普通对象指针。开启该选项后,下列指针将压缩至32位:
- 每个Class的属性指针(即静态变量)
- 每个对象的属性指针(即对象变量)
- 普通对象数组的每个元素指针
当然,也不是所有的指针都会压缩,一些特殊类型的指针JVM不会优化,比如指向PermGen的Class对象指针(JDK8中指向元空间的Class对象指针)、本地变量、堆栈元素、入参、返回值和NULL指针等。
对象头的大小
对象头 = Mark Word + 类型指针(未开启指针压缩的情况下)
在32位系统中,Mark Word = 4 bytes,类型指针 = 4bytes,对象头 = 8 bytes = 64 bits;
在64位系统中,Mark Word = 8 bytes,类型指针 = 8bytes,对象头 = 16 bytes = 128bits;
查看对象头
想要查看对象头中的数据,需要在项目中引入如下依赖:1
2
3
4
5<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
java示例代码:1
2
3
4
5
6
7
8
9
10public class ObjHeaderTest {
private int i;
public static void main(String[] args) {
ObjHeaderTest objHeaderTest = new ObjHeaderTest();
System.out.println(ClassLayout.parseInstance(objHeaderTest).toPrintable());
}
}
执行main方法得到结果:1
2
3
4
5
6
7
8com.lzumetal.jvm.ObjHeaderTest object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 int ObjHeaderTest.i 0
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
我使用的JDK版本是64位JDK1.8,但从输出的结果看对象头是12 bytes(3*4=12),并不是16 bytes。这是因为JVM默认是开启了指针压缩的。怎么关掉指针压缩再试一下呢?前面讲到-XX:+UseCompressedOops参数是开启指针压缩,把这个参数里的+改成-就是关掉指针压缩了,所以,我们在IDEA里加上-XX:-UseCompressedOops参数后再运行上面的main方法,可以得到如下结果:1
2
3
4
5
6
7
8
9
10com.lzumetal.jvm.ObjHeaderTest object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 28 30 f0 19 (00101000 00110000 11110000 00011001) (435171368)
12 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
16 4 int ObjHeaderTest.i 0
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
并且从上面看到对象里面的int类型数据用了4个字节存储,16+4=20,不是8的倍数,所以为了对齐,对象补了4个字节用24个字节存储。
锁的升级
JDK 1.6为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”,在JDK 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率,下文会详细分析。
偏向锁
什么是偏向锁
偏向锁是JDK 1.6中的重要引进,因为HotSpot作者经过研究实践发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低,引进了偏向锁。
当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地检测一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。如果有存储,表示线程已经获得了锁。如果没有存储,则需要再检查一下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁):如果没有设置,则用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
偏向锁是在只有一个线程执行同步块时进一步提高性能,适用于一个线程反复获得同一锁的情况。偏向锁可以提高带有同步但无竞争的程序性能。
偏向锁的撤销
偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。
偏向锁的撤销,需要等待全局安全点(在这个时间点上没有正在执行的字节码)。它会首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否活着,如果线程不处于活动状态,则将对象头设置成无锁状态;如果线程仍然活着,拥有偏向锁的线程会被执行,等该线程执行完同步代码后,锁对象头的Mark Word要么重新偏向于其他线程,要么恢复到无锁或者标记对象不适合作为偏向锁,最后唤醒暂停的线程。下图中的线程1演示了偏向锁初始化的流程,线程2演示了偏向锁撤销的流程。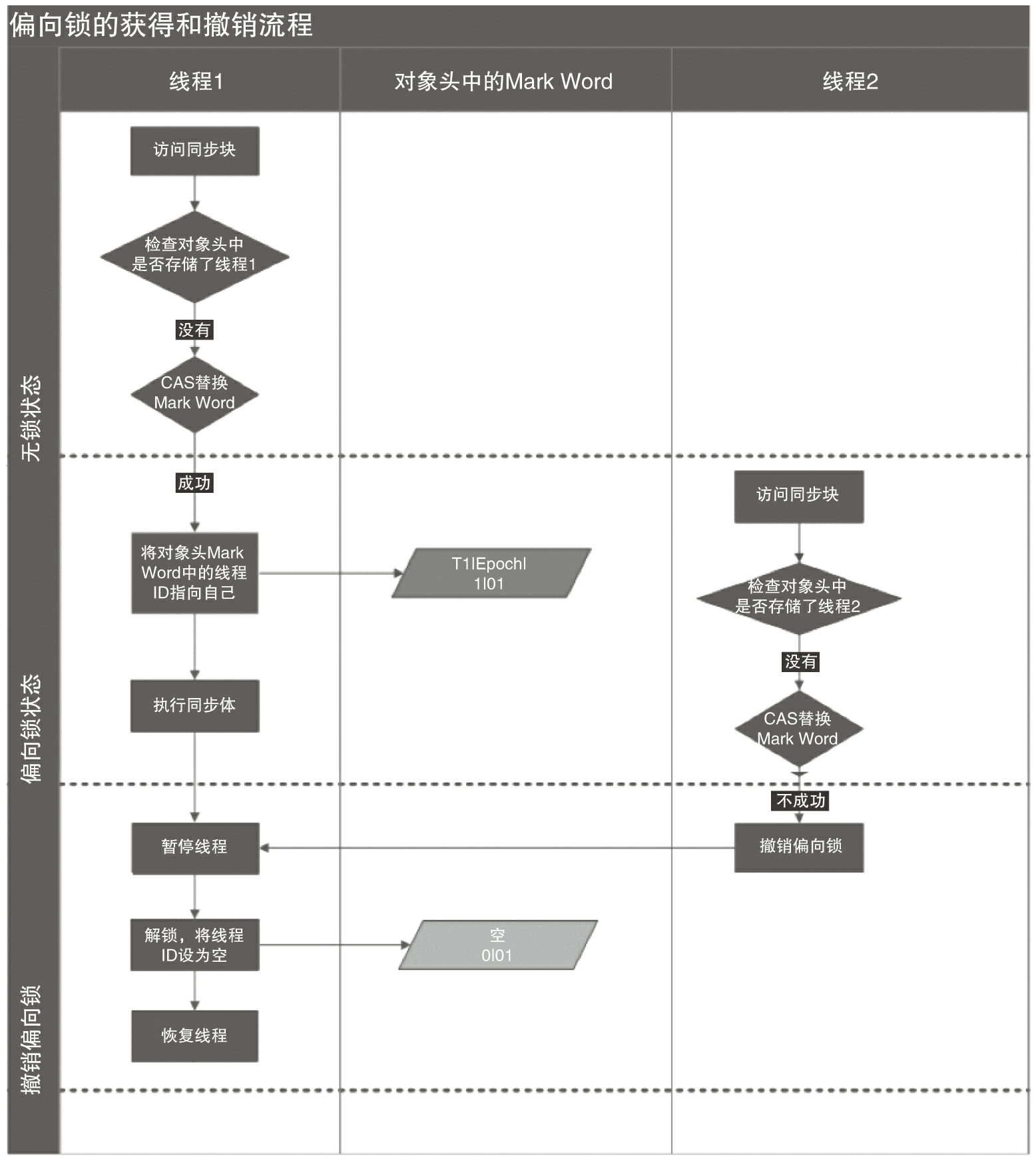
关闭偏向锁
偏向锁在JDK 1.6和JDK 1.7里是默认启用的,但是它在应用程序启动几秒钟之后才激活,如有必要可以使用JVM参数来关闭延迟:-XX:BiasedLockingStartupDelay=0。如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
偏向锁代码演示
测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class BiasedLockTest {
public static void main(String[] args) {
BiasedLockTaskThread thread = new BiasedLockTaskThread();
thread.start();
}
static class BiasedLockTaskThread extends Thread {
static final Object obj = new Object();
public void run() {
for (int i = 0; i < 3; i++) {
synchronized (obj) {
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}
}
}
JVM运行参数设置-XX:BiasedLockingStartupDelay=0,然后看运行结果。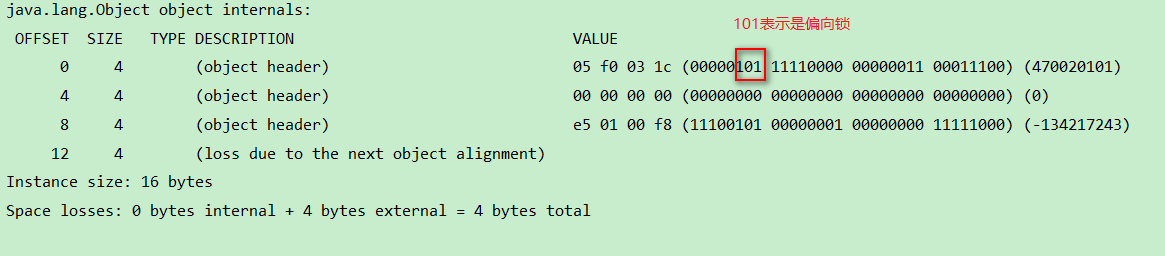
轻量级锁
什么是轻量级锁
轻量级锁是相对于JDK 1.6之前synchronized传统的锁机制而言的,首先需要强调一点的是,轻量级锁并不是用来代替重量级锁的。
引入轻量级锁的目的:在多线程交替执行同步块的情况下,尽量避免重量级锁引起的性能消耗,但是如果多个线程在同一时刻进入临界区,会导致轻量级锁膨胀升级重量级锁,所以轻量级锁的出现并非是要替代重量级锁。
当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,其步骤如下:
- 判断当前对象是否处于无锁状态(hashcode、0、01),如果是,则JVM首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝(官方把这份拷贝加了一个Displaced前缀,即Displaced Mark Word),将对象的Mark Word复制到栈帧中的Lock Record中,将Lock Reocrd中的owner指向当前对象。
- JVM利用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,如果成功表示竞争到锁,则将锁标志位变成00,执行同步操作。
- 如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
轻量级锁的释放
轻量级锁的释放也是通过CAS操作来进行的,主要步骤如下:
- 用CAS操作将取出的数据替换当前对象的Mark Word中,如果成功,则表示没有竞争发生。
- 如果CAS操作替换失败,说明有其他线程尝试获取该锁,则需要将轻量级锁需要膨胀升级为重量级锁。
如下图是两个线程同时争夺锁,导致锁膨胀的流程图。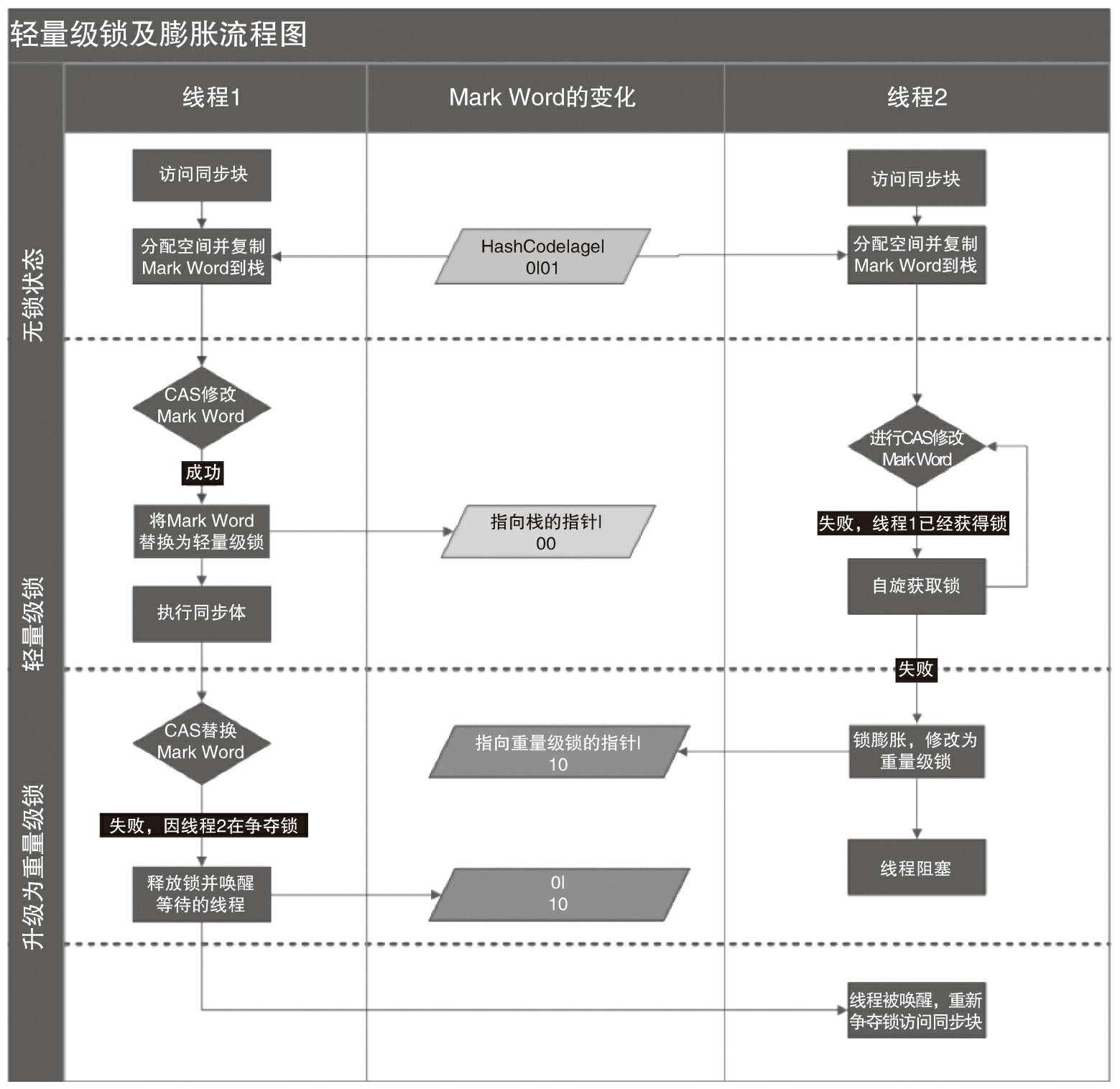
升级为重量级锁
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。当锁处于轻量级锁状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
自旋锁
上节讲到轻量级锁在发生锁竞争时会升级为重量级锁,但重量级锁的效率不高,因为线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,这些操作会降低系统的性能,所以在升级为重量级锁的过程中线程也会挣扎一下,会用到自旋锁去获取锁,参考上图中的线程2。
这是因为虚拟机的开发团队也注意到在许多应用上,共享数据的锁定状态只会持续很短的一段时间,为了这段时间阻塞和唤醒线程并不值得。如果物理机器有一个以上的处理器,能让两个或以上的线程同时并行执行,我们就可以让后面请求锁的那个线程“稍等一下”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需让线程执行一个忙循环(自旋) , 这项技术就是所谓的自旋锁。
自旋锁在JDK 1.4.2中就已经引入 ,只不过默认是关闭的,可以使用-XX:+UseSpinning参数来开启,在JDK 1.6中就已经改为默认开启了。自旋等待不能代替阻塞,且先不说对处理器数量的要求,自旋等待本身虽然避免了线程切换的开销,但它是要占用处理器时间的,因此,如果锁被占用的时间很短,自旋等待的效果就会非常好,反之,如果锁被占用的时间很长。那么自旋的线程只会白白消耗处理器资源,而不会做任何有用的工作,反而会带来性能上的浪费。因此,自旋等待的时间必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程了。自旋次数的默认值是10次,用户可以使用参数-XX : PreBlockSpin来更改。
适应性自旋锁
在JDK 1.6中引入了自适应的自旋锁。自适应意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而它将允许自旋等待持续相对更长的时间,比如100次循环。另外,如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。有了自适应自旋,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测就会越来越准确,虛拟机就会变得越来越“聪明”了。
锁消除
锁消除是指虚拟机即时编译器(JIT)在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持,如果判断在一段代码中,堆上的所有数据都不会逃逸出去从而被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁自然就无须进行。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是程序员自己应该是很清楚的,怎么会在明知道不存在数据争用的情况下要求同步呢?实际上有许多同步措施并不是程序员自己加入的,同步的代码在Java程序中的普遍程度也许超过了大部分读者想象。下面这段非常简单的代码仅仅是输出3个字符串相加的结果,无论是源码字面上还是程序语义上都没有同步。
1 | public class NonLockDemo { |
StringBuffer的append( )是一个同步方法,锁就是this也就是(new StringBuilder())。虚拟机发现它的动态作用域被限制在concatString( )方法内部。也就是说, new StringBuilder()对象的引用永远不会“逃逸”到concatString( )方法之外,其他线程无法访问到它,因此,虽然这里有锁,但是可以被安全地消除掉,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了。
面试题
synchroznied出现异常会释放锁吗?
答案:会释放锁。synchronized与Lock的区别
- synchronized是关键字,而Lock是一个接口。
- synchronized会自动释放锁,而Lock必须手动释放锁。
- synchronized是不可中断的,Lock可以中断也可以不中断。
- 通过Lock可以知道线程有没有拿到锁,而synchronized不能。
- synchronized能锁住方法和代码块,而Lock只能锁住代码块。
- Lock可以使用读锁提高多线程读效率。
- synchronized是非公平锁,ReentrantLock可以控制是否是公平锁。
平时写代码如何对synchronized优化
- 减少synchronized的范围。同步代码块中尽量短,减少同步代码块中代码的执行时间,减少锁的竞争。
- 降低synchronized锁的粒度。可以参考 ConcurrentHashMap 相对于 HashTable 所做的优化。
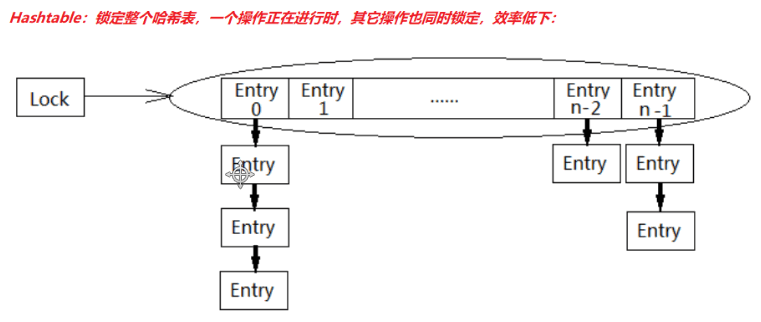
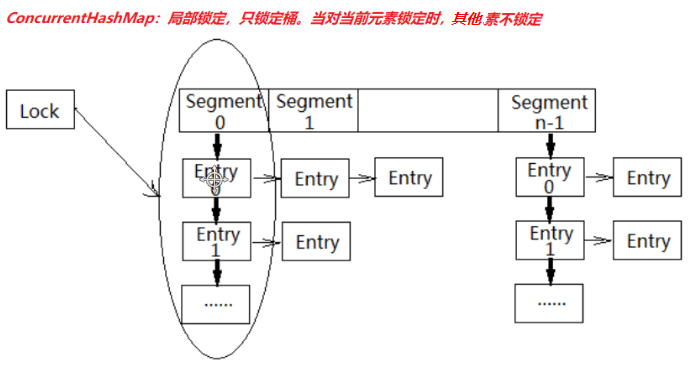
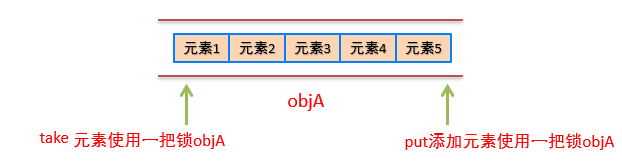
LinkedBlockingQueue入队和出队使用不同的锁,相对于读写只有一个锁效率要高。

- 读写分离。读取时不加锁,写入和删除时加锁,例如 ConcurrentHashMap,CopyOnWriteArrayList 和 ConyOnWriteSet 这些类。