在并发编程中的基础概念一文中,提到了并发变编程中的可见性问题,在Java中则是使用volatile关键字解决可见性问题的。除了这点,volatile也还能对CPU的指令重排序起一定的限制作用。
volatile关键字
当一个变量被volatile关键字修饰之后,则具有了两层语义:
- 保证了该变量在多个线程的可见性
即每个线程能够获取到该变量的最新值,从而避免出现数据脏读的现象。 - 会通过Lock指令禁止特定类型的指令重排序
volatile的实现原理
内存屏障(memory barriers)
内存屏障实际上就是一组lock指令。在X86处理器下通过工具获取JIT编译器生成的汇编指令来查看对volatile进行写操作,CPU会执行写什么命令呢?
Java代码如下:1
instance = new Singleton(); //instance是volatile变量
转变成汇编代码如下:1
20x01a3de1d: movb $0X0,0X1104800(%esi);
0x01a3de24: lock addl $0X0,(%esp);
有volatile修饰的共享变量进行写操作时会多出第二行汇编代码,该句代码的意思是对原值加零,其中相加指令addl前有lock修饰。通过查IA-32架构软件开发者手册可知,lock前缀的指令会提供3个功能:
- 它会强制将当前处理器缓存行的数据写回到系统内存。
- 如果是写操作,它会使在其他CPU里缓存了该内存地址的数据无效。
- 禁止特定类型的重排序。它确保指令重排序时不会把其后面的指令排到lock指令之前的位置,也不会把前面的指令排到lock指令的后面。即在执行到lock指令时,在它前面的操作已经全部完成。
在JSR规范中定义了4种内存屏障:
- StoreStore屏障:禁止上面的普通写和下面的volatile写重排序;
- StoreLoad屏障:防止上面的volatile写与下面可能有的volatile读/写重排序
- LoadLoad屏障:禁止下面所有的普通读操作和上面的volatile读重排序
- LoadStore屏障:禁止下面所有的普通写操作和上面的volatile读重排序
JMM采取的策略是:
- 在每个volatile写操作的前面插入一个StoreStore屏障;
- 在每个volatile写操作的后面插入一个StoreLoad屏障;
- 在每个volatile读操作的后面插入一个LoadLoad屏障;
- 在每个volatile读操作的后面插入一个LoadStore屏障。
需要注意的是:volatile写是在前面和后面分别插入内存屏障,而volatile读操作是在后面插入两个内存屏障。
如下两张图来自《Java并发编程的艺术》一书:
- volatile变量的写操作
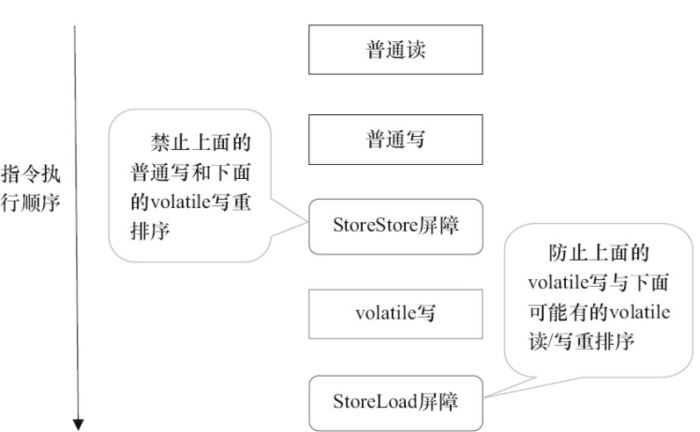
- volatile变量的写操作
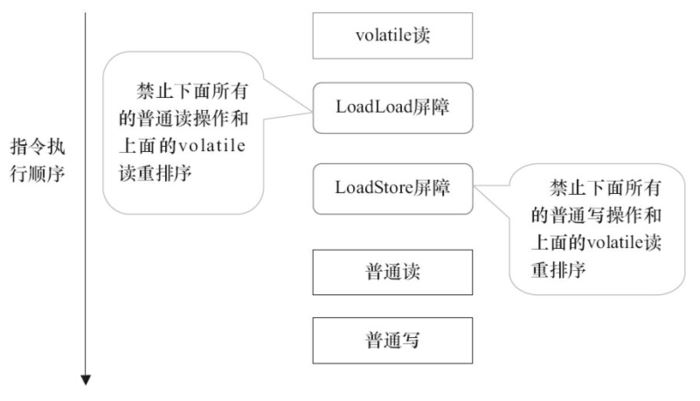
根据上面的说明也能得出:虽然volatile关键字能禁止指令重排序,但是volatile也只能在一定程度上保证有序性。在volatile之前和之后的指令集不会乱序越过volatile变量执行,但volatile之前和之后的指令集在没有关联性的前提下,仍然会执行指令重排。
可见性
voiatile的可见性是Java语言层面给出的一种缓存一致性保证。
在并发编程中的基础概念文章中提到过CPU的缓存一致性以及经典的MESI协议,就拿MESI协议来说,并不是所有的CPU都支持MESI协议,而且MESI只是保证了L1-3 的缓存一致性,但是cpu的并不是直接把数据写入L1 cache的,中间还可能有store buffer。有些arm和power架构的cpu还可能有load buffer或者invalid queue等等,因此只靠MESI这种协议是无法保证变量的可见性的。voiatile是JMM(Java内存模型)在CPU核心、操作系统等层面上进行的封装,它屏蔽了内核和底层操作系统的差异,让开发人员可以安心地做并发编程。其具体的实现细节可能非常复杂,MESI协议只是它在某种特定情况中需要使用到的一个细节。
禁止特定的指令重排序
在并发编程中的基础概念文中提到了JMM,JMM为了性能考虑,并没有禁止编译器和CPU的指令重排序。所以在JMM体系中,指令重排序仍然是会发生的。但JMM也可以通过内存屏障(memory barriers)对重排序进行一定限制,调整程序的指令最终被执行的顺序。
volatile的使用情形
double-check 单例模式
单例模式有一种double-check写法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Singleton {
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) { //1
syschronized(Singleton.class) { //2
if (instance == null) { //3
instance = new Singleton(); //4
}
}
}
return instance;
}
}
为什么要用volatile修饰才是最安全的呢?可能有人会觉得是这样:线程1执行完第4步,释放锁。线程2获得锁后执行到第4步,由于可见性的原因,发现instance还是null,从而初始化了两次。
但是不会存在这种情况,因为synchronized能保证线程1在释放锁之前会讲对变量的修改刷新到主存当中,线程2拿到的值是最新的。
实际存在的问题是无序性。
第4步这个new操作是无序的,它可能会被编译成:
a. 先分配内存,让instance指向这块内存
b. 在内存中创建对象
synchronized虽然是互斥的,但不代表一次就把整个过程执行完,它在中间是可能释放时间片的,时间片不是锁。
也就是说可能在a执行完后,时间片被释放,线程2执行到1,此时它读到的instance是不是null呢?答案是:不确定,可能是null,也可能不是null。 有意思的是,在这个例子中,如果读到的是null,反而没问题了,接下来会等待锁,然后再次判断时不为null,最后返回单例。
如果读到的不是null,按代码逻辑直接return instance,但这个instance还没执行构造参数,所以使用的时候就会出现问题。
修饰状态标志量
1 | volatile boolean shutdownRequested; |
在这个示例使用 synchronized 块编写循环要比使用 volatile 状态标志编写麻烦很多。由于 volatile 简化了编码,并且状态标志并不依赖于程序内任何其他状态,因此此处非常适合使用 volatile。
注意点
volatile无法保证原子性
例如i++的操作就无法通过volatile保证结果准确性的,因为i++包含了读取-修改-写入三个步骤,并不是一个原子操作,所以 volatile 变量不能用作线程的安全计数器。
下面的这段代码可以做一个验证:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public class Counter {
private volatile static int count = 0;
private static final int THREADS_COUNT = 10;
private static CountDownLatch countDownLatch = new CountDownLatch(THREADS_COUNT);
private static void increase() {
count++;
}
public static void main(String[] args) throws InterruptedException {
//同时启动10个线程,每个线程进行1万次i++计算
for (int i = 0; i < THREADS_COUNT; i++) {
new Thread(() -> {
for (int j = 0; j < 10000; j++) {
increase();
}
countDownLatch.countDown();
}).start();
}
countDownLatch.await();
System.out.println("运行结果:Counter.count=" + Counter.count); //结果会<100000
}
}
运行计数器的结果很大可能性是<100000的。对于计数器的这种功能,一般是需要使用JUC中atomic包下的类,利用CAS的机制去做。
volatile无法提供理想的线程安全
volatile并不能代替synchronized,因为它并不能保证理想的线程安全。