从计算机的存储系统说起
计算机的存储系统以一种分层次的结构构造,如下图所示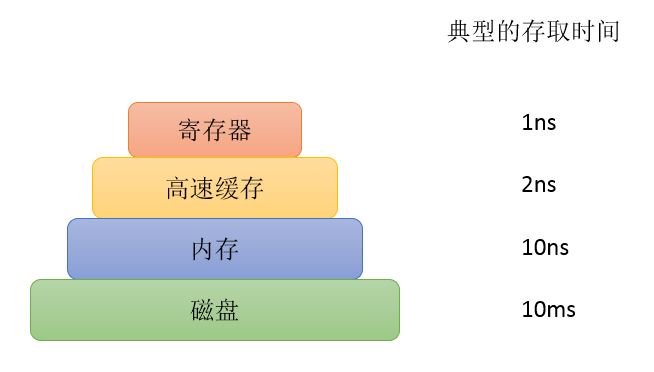
- 寄存器。存储器的顶层是CPU的寄存器。它们用与CPU相同的材料和工艺制成,其存取速度和CPU的运行速度一样快。
寄存器是什么?
CPU工作时需要从内存中取出指令并执行,但是通过访问内存得到指令和数据的时间要比执行花费的时间长得多,所以CPU都有一些用来保存关键变量和临时结果的寄存器。另外还有程序计数器、堆栈指针寄存器和程序状态字寄存器等,都有各自的功能。 高速缓存。计算机无法仅靠CPU和寄存器就完成所有运算任务,CPU至少要与内存交互,如读取运算数据、存储运算结果等。但内存的读写速度与CPU的运算速度有几个数量级的差距,所以现代计算机会在 CPU和内存中间增加高速缓存。高速缓存被分割成缓存行(Cache Line)。
缓存行是什么?
缓存行可以简单理解为CPU高速缓存中的最小存储单元。当前主流CPU缓存行大小典型值是64byte(有的CPU是32byte,跟CPU型号有关)。
当CPU需要某个数据时,会先去高速缓存中查找,如果找到了,称为高速缓存命中,也就不需要通过总线将请求发往内存。高速缓存如果未命中则需要访问内存,这比直接访问CPU内的高速缓存要慢很多。如下是最简单的高速缓存示意图:
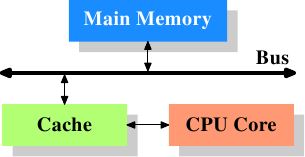
早期的一些系统就是类似的架构。在这种架构中,CPU核心不会直连到主存。数据的读取和存储都经过高速缓存。CPU核心与高速缓存之间是一条特殊的快速通道。在简化的表示法中,主存与高速缓存都连到系统总线上,这条总线同时还用于与其它组件(比如硬盘控制器、键盘控制器等)通信。在高速缓存出现后不久,系统变得更加复杂。高速缓存与主存之间的速度差异进一步拉大,直到加入了另一级缓存。新加入的这一级缓存比第一级缓存更大,但是更慢。由于加大一级缓存的做法从经济上考虑是行不通的,所以有了二级缓存,现在很多高级的CPU上还会有三级缓存,如下图:
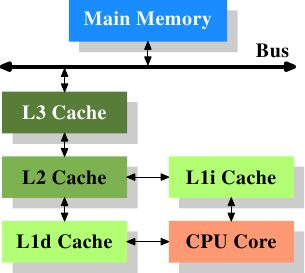
此外,图中还可以看到一级缓存(L1 Cache)被分为了L1i Cache(用来缓存指令)和L1d Cache(用来缓存数据)。
内存(Main Memory,又称主存),这是存储系统的主力。所有不能在高速缓存中命中的访问请求都会转往内存。
- 磁盘(硬盘),也称为外存。由于磁盘的机械结构导致其访问速度很慢。
什么是上下文切换?
《Java并发编程的艺术》中是这样描述的:
即使是单核处理器也支持多线程执行代码,CPU通过给每个线程分配CUP时间片来实现这个机制。时间片是CPU分配给各个线程的时间,因为时间片非常短,所以CPU通过不停地切换线程执行,让我们感觉多个线程时同时执行的,时间片一般是几十毫秒(ms)。
CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再次加载的过程就是一次上下文切换。
计算机内存模型的缓存一致性问题
缓存一致性
计算机在执行程序时,每条指令都是由CPU执行,执行指令过程中,必定会涉及到数据的读取和写入。程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,根据前面所说的,现代计算机的CPU执行速度越来越快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此在CPU和内存之间加入了高速缓存。
缓存的引入很好地解决了CPU与内存的速度矛盾,但它却带来了一个新的问题:缓存一致性(Cache Coherence)。
当程序在运行过程中,会将运算需要的数据从内存复制一份到CPU的缓存当中,那么CPU进行计算时就可以直接从它的缓存读取数据和向其中写入数据,当运算结束之后,再将缓存中的数据刷新到内存中。举个简单的例子,比如下面的这句代码逻辑:
i = i + 1;
当线程执行这个语句时,会先从内存当中读取i的值,然后复制一份到缓存当中,然后CPU执行指令对i进行加1操作,然后将执行完的结果写入缓存,最后将缓存中i最新的值刷新到内存中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
我们知道整个过程应该是:两个线程首先都要从内存中读取i的值存入到各自所在的CPU的缓存中,然后两个线程各自进行加1操作,最后各自把i的最新值写入到内存。但可能存在这样一种情况:线程1首先读取了i的值是0,然后进行加1,在没有将结果刷新的内存之前,如果线程2此时读取内存中的值也会是0,线程2同样自己进行加1操作。最终两个线程计算的结果都是1,不管是线程1还是线程2先将结果刷新到内存中,内存中的i最终的值都是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。(注意:这段过程分析是以i = i + 1是非原子性操作为前提的)

也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
- 通过在总线加LOCK#锁的方式(锁总线)
- 通过缓存一致性协议(锁缓存)
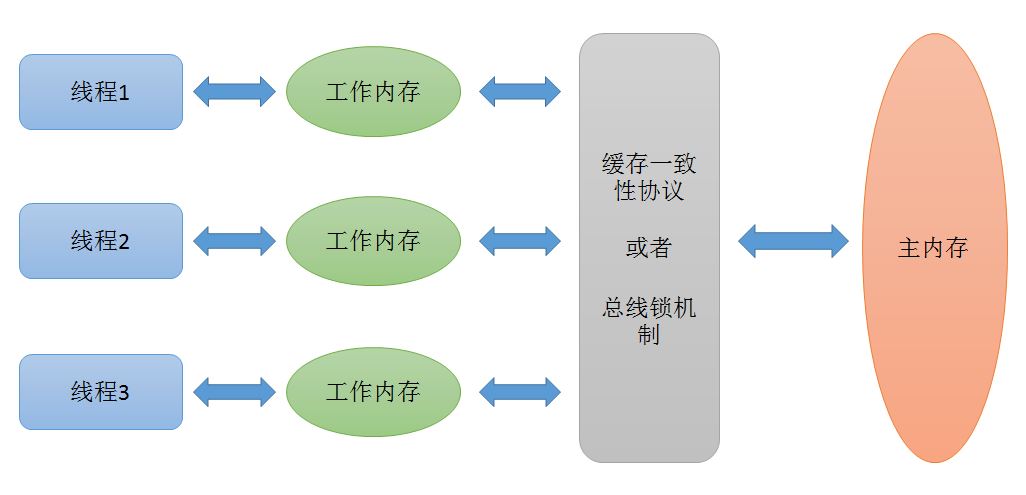
总线锁定
总线锁定就是使用处理器想总线上输出一个LOCK#信号。因为CPU和其他部件通信都是通过总线来进行,如果对总线加LOCK#锁的话,也就阻塞了其他CPU对其他部件的访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。
比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取i变量,然后进行相应的操作。
缓存锁定
对于总线锁的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问一个内存地址,导致效率低下,所以就出现了缓存锁定。最出名的就是MESI(修改、独占、共享、无效)协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:多核CPU工作的时候,通过嗅探技术发现操作的变量(变量的实质是内存中的一个地址)如果是共享变量(即在其他CPU中也存在该变量的副本),并且其它CPU修改了这个变量,那么当前CPU会将该变量的缓存置为无效状态,因此当前CPU需要操作这个变量时,它会从内存中去读取最新的值。
指令重排序
什么是指令重排序?一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
重排序的种类:
- 编译期重排。编译源代码时,编译器依据对上下文的分析,对指令进行重排序,以之更适合于CPU的并行执行。
- 运行期重排,CPU在执行过程中,动态分析依赖部件的效能,对指令做重排序优化。
举个例子(这里严格来说应该是要用cpu指令集来举例,便于理解直接使用Java代码的方式),对于下面这段代码:1
2
3
4int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,因为这里可能会发生指令重排序(Instruction Reorder)。
对于上面的代码,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:1
2
3
4int a = 10; //语句1
int r = 2; //语句2
a = a + 3; //语句3
r = a*a; //语句4
这段代码有4个语句,那么可能的一个执行顺序是:
那么可不可能是这个执行顺序呢: 语句2——>语句1——>语句4——>语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
1 | //线程1: |
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
所以,指令重排序不会影响单个线程的执行,但是会影响到多线程执行的正确性。