本文示例使用的VMWare虚拟机,Linux系统版本是CentOS 7_64位,Hadoop的版本是Hadoop 2.8.2,JDK版本是1.8。
Hadoop有三种启动模式:
- 单机模式:Hadoop被配置成以非分布式模式运行的一个独立Java进程。这种模式适合用于调试。
- 伪分布式模式:Hadoop可以在单节点上以所谓的伪分布式模式运行。此时每一个Hadoop守护进程,如 hdfs, yarn, MapReduce 等,都将作为一个独立的java程序运行。这种模式适合用户开发。
- 完全分布式模式:即真正的分布式,需要多台独立服务器组成集群。
本文内容即是单机模式的示例。单机模式下不会启动HDFS和YARN进程,只用于向
安装前的准备
1.创建Hadoop用户
先以root用户登录,然后使用下面命令创建一个名为hadoop的新用户1
useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为shell。
接着使用如下命令修改密码,1
passwd hadoop
按提示输入两次密码,可简单的设为 “hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行)。
可为 hadoop 用户增加管理员权限,方便部署,避免一些比较棘手的权限问题(生产环境不建议此做法),执行:1
visudo
如下图,找到 root ALL=(ALL) ALL 这行(应该在第98行),在这行下面增加一行内容:hadoop ALL=(ALL) ALL (当中的间隔为tab),如下图所示: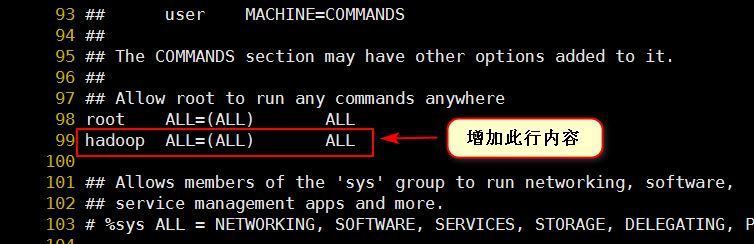
最后,使用新创建的hadoop用户远程登录,然后查看现在是哪个用户执行:
下载Hadoop并配置
从官网上 http://hadoop.apache.org/releases.html 下载,并解压到服务器的某个目录下(此处我登录的用户是hadoop,解压到${HOME}/app目录下)。
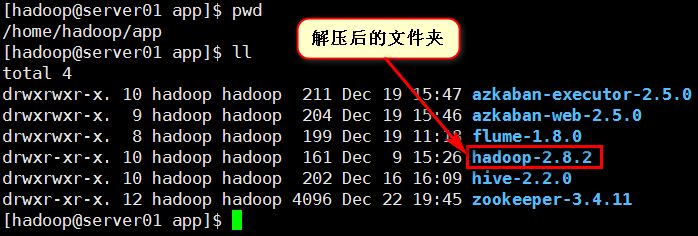
在Hadoop的运行环境配置文件中配置Java的安装目录
编辑${HADOOP_HOME}/etc/hadoop/hadoop-env.sh文件,将JAVA_HOME设置为Java安装根路径。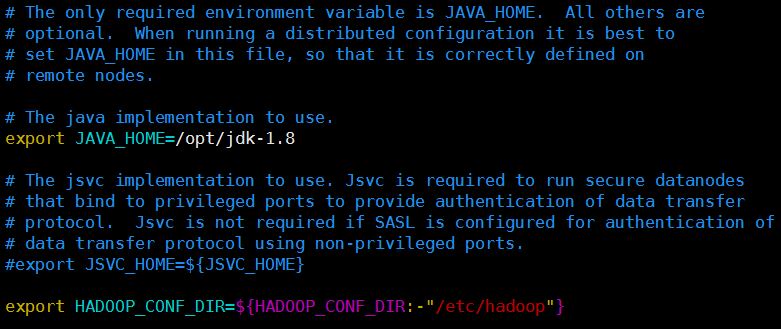
配置Hadoop的环境变量
在/etc/profile文件中增加:1
2export HADOOP_HOME=/opt/hadoop-2.8.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin比如我的
/etc/profile设置成如下图: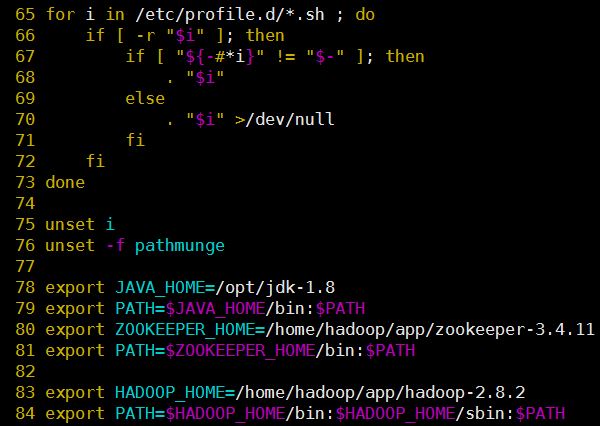
执行
hadoop version命令,验证验证环境变量是否配置成功,正常情况下会看到类似如下的结果:1
2
3
4
5
6
7
8[hadoop@server01 hadoop]$ hadoop version
Hadoop 2.8.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 66c47f2a01ad9637879e95f80c41f798373828fb
Compiled by jdu on 2017-10-19T20:39Z
Compiled with protoc 2.5.0
From source with checksum dce55e5afe30c210816b39b631a53b1d
This command was run using /home/hadoop/app/hadoop-2.8.2/share/hadoop/common/hadoop-common-2.8.2.jar
[hadoop@server01 hadoop]$
使用示例
Hadoop自带了一个MapReduce程序$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar,它作为一个例子提供了MapReduce的基本功能,并且可以用于计算,包括 wordcount、terasort、join、grep 等。
以通过执行如下命令查看该.jar文件支持哪些MapReduce功能。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar
1 | [hadoop@server01 mapreduce]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar |
接下来我们就演示如何使用这个自带的MapReduce程序来计算文件中单词的个数。
创建一个目录用来存放我们要处理的数据,可以创建在任何地方(这里我是在
/home/hadoop/hadoopdata的目录下创建一个input的目录),并把想要计算分析的文件放到这个目录下(这里我把Hadoop的配置文件复制一份到input目录下)。cd /home/hadoop/hadoopdata mkdir input cp /home/hadoop/app/hadoop-2.8.2/etc/hadoop/*.xml input ll input1
2
3
4
5
6
7
8
9
10
11
12
13[hadoop@server01 hadoopdata]$ cp /home/hadoop/app/hadoop-2.8.2/etc/hadoop/*.xml input
[hadoop@server01 hadoopdata]$ ll input
total 52
-rw-r--r--. 1 hadoop hadoop 4942 Apr 30 11:43 capacity-scheduler.xml
-rw-r--r--. 1 hadoop hadoop 1144 Apr 30 11:43 core-site.xml
-rw-r--r--. 1 hadoop hadoop 9683 Apr 30 11:43 hadoop-policy.xml
-rw-r--r--. 1 hadoop hadoop 854 Apr 30 11:43 hdfs-site.xml
-rw-r--r--. 1 hadoop hadoop 620 Apr 30 11:43 httpfs-site.xml
-rw-r--r--. 1 hadoop hadoop 3518 Apr 30 11:43 kms-acls.xml
-rw-r--r--. 1 hadoop hadoop 5546 Apr 30 11:43 kms-site.xml
-rw-r--r--. 1 hadoop hadoop 871 Apr 30 11:43 mapred-site.xml
-rw-r--r--. 1 hadoop hadoop 1067 Apr 30 11:43 yarn-site.xml
[hadoop@server01 hadoopdata]$在这个例子中,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,在
/home/hadoop/hadoopdata目录下执行如下命令启动Hadoop进程。hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar grep input output 'dfs[a-z.]+'执行成功的话,会打印一系列处理的信息,处理的结果会输出到 output 文件夹中,通过命令 cat output/* 查看结果,符合正则的单词 dfsadmin 出现了1次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=123
File Output Format Counters
Bytes Written=23
[hadoop@server01 hadoopdata]$ cat output/*
1 dfsadmin
[hadoop@server01 hadoopdata]$ ll output/
total 4
-rw-r--r--. 1 hadoop hadoop 11 Apr 30 12:51 part-r-00000
-rw-r--r--. 1 hadoop hadoop 0 Apr 30 12:51 _SUCCESS
[hadoop@server04 hadoopdata]$
注意,Hadoop 默认不会覆盖结果文件,因此再次运行一个命令并且结果也是输出到output目录则会提示出错,需要先将 output 目录删除。
删除output目录后我们使用命令在计算一下单词数:
1
2[hadoop@server04 hadoopdata]$ rm -rf output/
[hadoop@server04 hadoopdata]$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar wordcount input output查看结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15File Input Format Counters
Bytes Read=26548
File Output Format Counters
Bytes Written=10400
[hadoop@server04 hadoopdata]$ cat output/*
"*" 18
"AS 8
"License"); 8
"alice,bob 18
"clumping" 1
"kerberos". 1
"simple" 1
'HTTP/' 1
'none' 1
'random' 1
这样我们就利用Hadoop自带的MapReduce程序成功地运行了它计算单词个数的功能。